Embodied AI: How Language Models Are Powering the Next Generation of Robots
Embodied AI is merging language models with physical robots. Learn how VLMs and LLMs are solving the perception-to-action gap and what it means for 2026 and beyond.
What Is Embodied AI?
For decades, artificial intelligence lived mostly in software. Classic AI systems could play chess. They could translate languages. They could even generate art. But they had no body. They could not pick up a cup. They could not navigate a messy kitchen. They could not adapt when something went wrong.
Embodied AI changes this by requiring an AI agent to have a physical presence. That agent must sense its environment, act upon it, and learn from the results. The body is not an accessory. It is a fundamental part of the system. This idea traces back to the embodiment hypothesis in cognitive science. That hypothesis, articulated by researchers at MIT and elsewhere, states that intelligence cannot be fully realized without a body interacting with the physical world.
This creates a fundamentally different engineering challenge. A large language model only needs to predict the next token. An embodied AI system must close the loop between perception, reasoning, and motor control in real time. It must handle unstructured environments. It must adapt when objects move, when surfaces change, when humans behave unexpectedly.
By 2026, this is no longer a purely theoretical problem. Multiple humanoid robot platforms have reached real deployments in facilities ranging from automotive manufacturing plants to Scandinavian eldercare homes. The question is no longer whether embodied AI is possible. The question is how quickly it will transform industries.
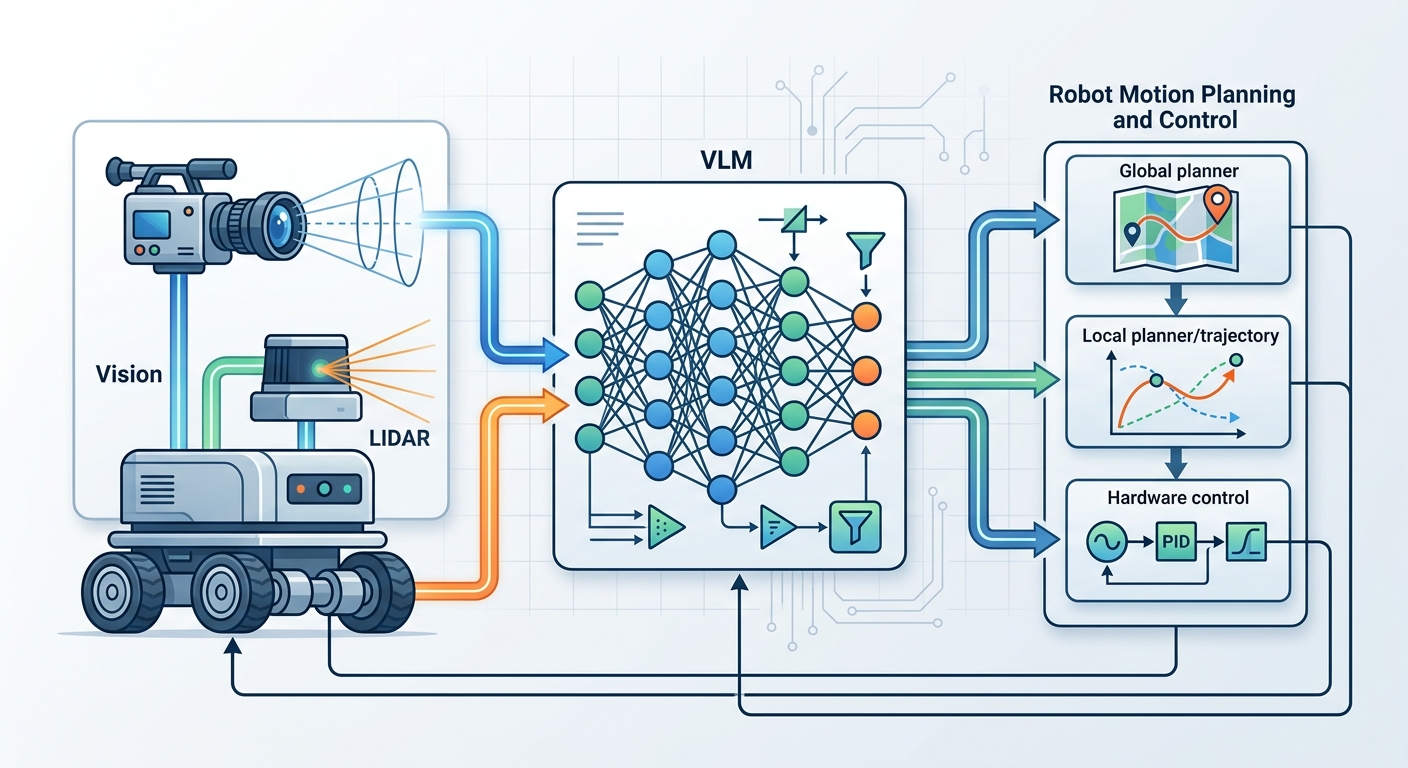
Why Language Models Are a Game-Changer for Robots
Before large language models, programming a robot for a new task meant writing explicit code. Engineers would break down every step. They would define conditions. They would handle exceptions one by one. This process was slow, brittle, and expensive. A robot programmed to sort packages in one warehouse could not pour coffee in a kitchen.
Large language models (LLMs) changed this by bringing pre-trained world knowledge to robots. LLMs are trained on text from across the internet. They learn that water is wet. They learn that a mug can hold liquid. They learn that pouring requires tilting. This "common sense" was previously invisible to software. It was the gap that kept robots from generalizing across tasks.
With an LLM as a reasoning layer, a robot can receive a natural-language instruction for a task it has never seen. It does not need a new script. The LLM breaks down the instruction into sub-tasks. It selects relevant knowledge. It generates a plan. This is called zero-shot task generalization — a capability that allows the robot to adapt to a new object or environment without any retraining.
Chain-of-thought prompting extends this further. The robot can reason step by step. It can ask itself: "What do I need to grasp? Where is it? What angle should my arm take?" This inner dialogue was impossible before LLMs. It allows for multi-step tasks that would overwhelm a classical planning system.
The practical impact is significant across multiple industries. In manufacturing, a single robot base can be redeployed to new product lines using voice commands. In logistics, the same robot can sort boxes of different sizes because it understands shape and capacity from language descriptions. Research published by teams at Stanford and Carnegie Mellon has demonstrated that language models have effectively solved the long-horizon planning problem that stymied classical robotics for decades.
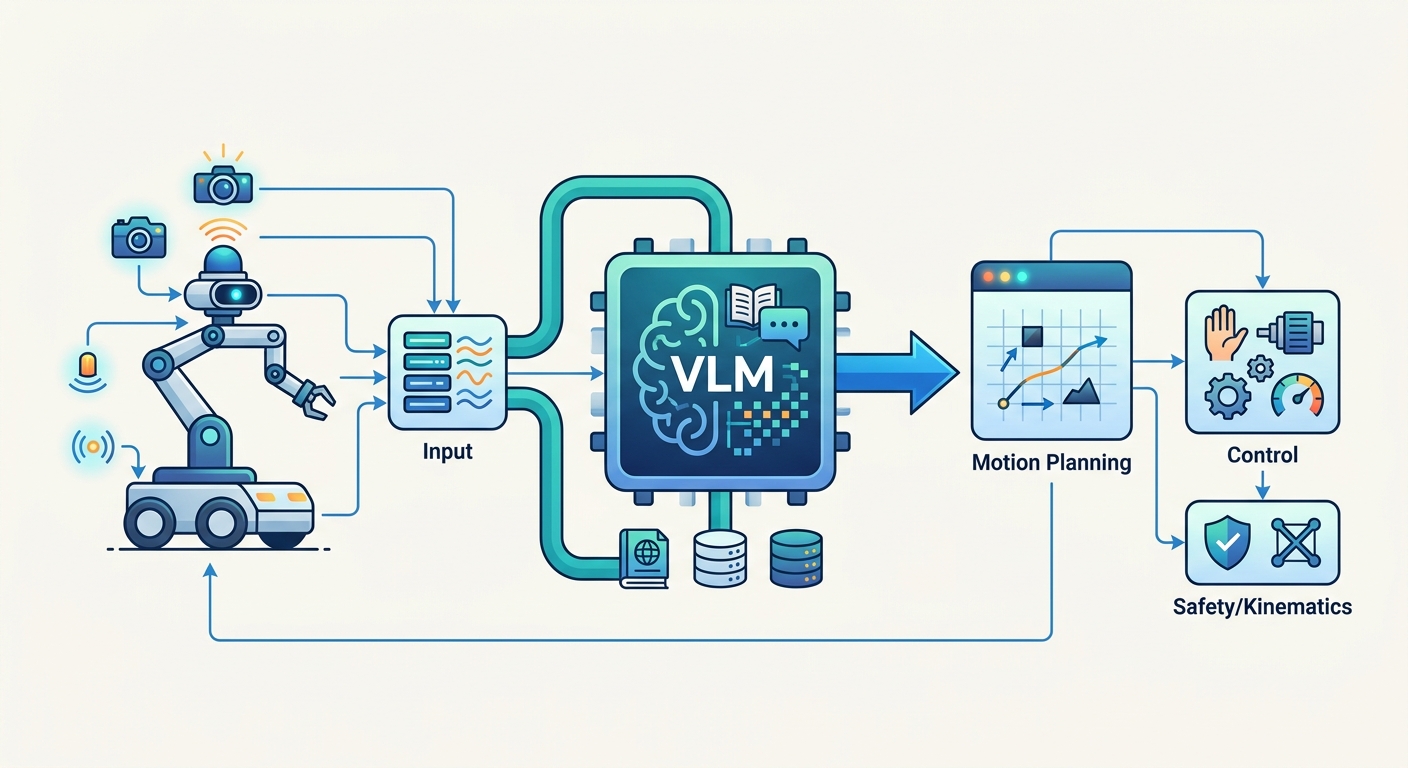
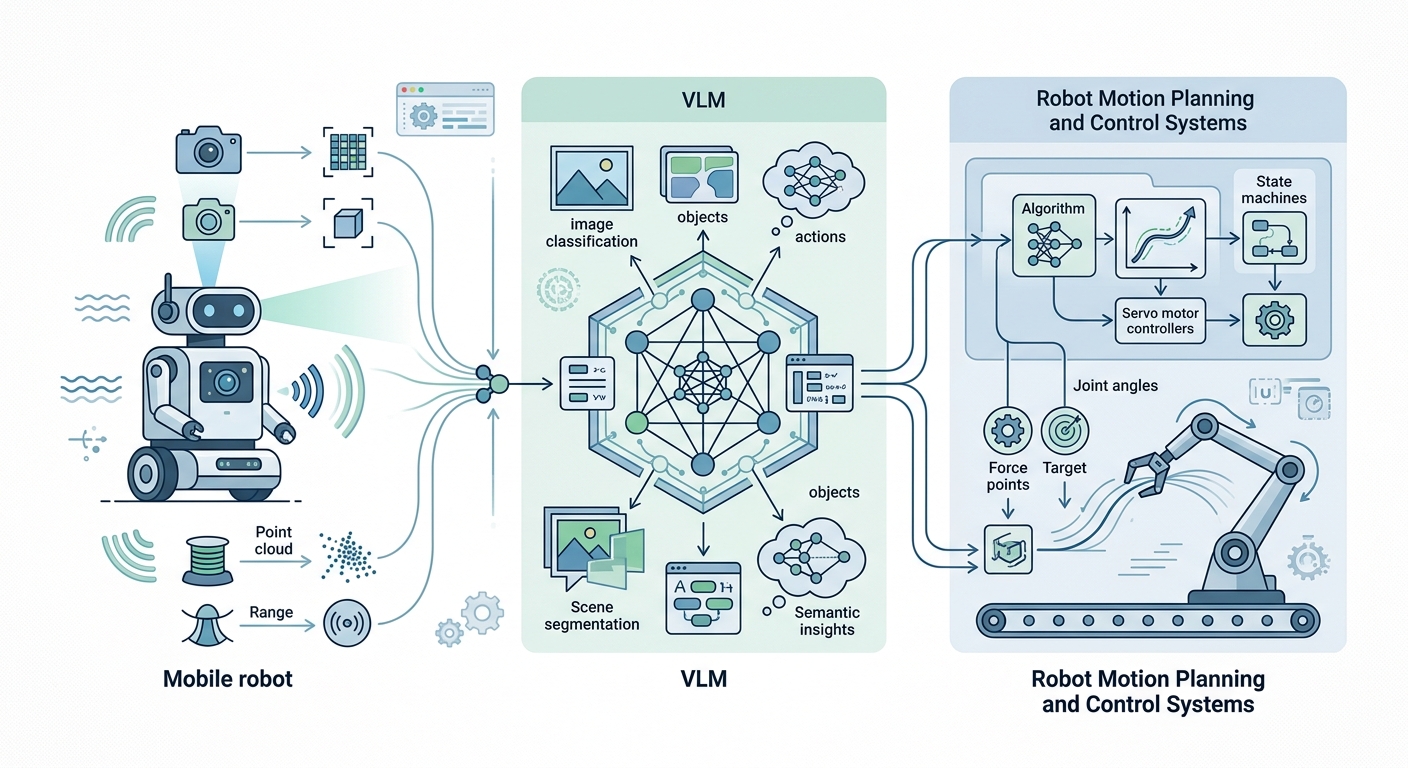
Vision-Language Models: Giving Robots "Eyes and a Brain"
An LLM on its own has no visual input. It processes text. For a robot to navigate the real world, it needs to see. This is where vision-language models (VLMs) become essential.
A VLM is a single model that processes both image frames and text tokens together. Well-known examples include GPT-4V (from OpenAI), PaLM-E (from Google DeepMind), and RT-2 (also from DeepMind). These models learned to reason about images the same way they learned to reason about text. They can describe what they see. They can answer questions about a scene. They can follow visual instructions.
For robots, VLMs enable something called open-vocabulary object detection. Classical robot vision systems are trained on a fixed list of objects. If a robot encounters something outside that list, it cannot identify or interact with it. A VLM-based system can detect and localize any object described in natural language. Show it a new tool. Ask it to "hand me the thing on the left." It can figure out what you mean.
RT-2 (Robotic Transformer 2) represents a significant architectural step. Published by Google DeepMind researchers in a 2023 paper, RT-2 is a vision-language-action model. Unlike previous systems that kept vision, language, and action as separate modules, RT-2 outputs robot action tokens directly. It learned to map visual inputs and language commands to motor commands through large-scale web data and robotic demonstrations. In benchmark testing, RT-2 showed the ability to generalize to novel tasks at rates exceeding prior approaches by a significant margin.
PaLM-E goes further by embedding continuous sensor data alongside text. Robots have proprioception: awareness of the position of their own limbs. They have depth sensors. They have force feedback. PaLM-E processes all of these signals together. The result is a robot that can reason about both what it sees and how its body is positioned in space simultaneously.
This combination enables what researchers call semantic grasping. A robot told to "grab something to stir the pot" can look at a drawer and infer that a spoon — not a fork — is the right tool for stirring. It makes this choice based on functional descriptions learned from language, not from a pre-programmed list of approved utensils.
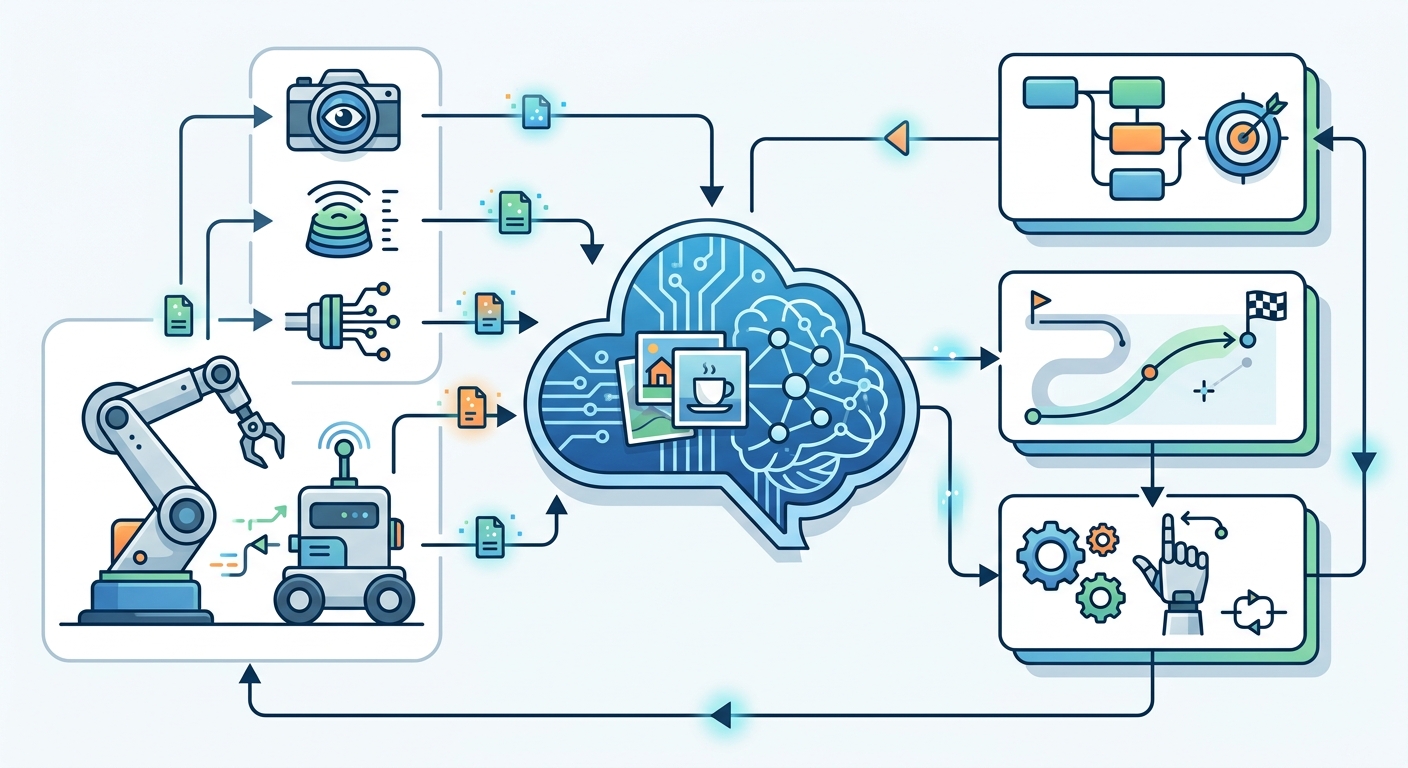
Key Technical Building Blocks
The integration of language models into robotics rests on several core technical advances. Understanding these helps clarify both what is working today and what remains an open problem.
Affordance Grounding
Affordances describe what an object can be used for. A flat, stable surface affords sitting. A handle affords grasping. A blade affords cutting. Language models can describe affordances in rich detail. The challenge is connecting those descriptions to physical objects in a robot's environment.
This mapping is called affordance grounding. A robot sees a knife and a pair of scissors. The task is "cut the rope." The LLM knows that both items could cut, but that scissors are safer and more precise for rope. The affordance model must then guide the robot's grasp and action to select scissors over the knife.
Modern approaches use language-conditioned affordance models trained with contrastive learning. Others use neuro-symbolic pipelines. These pipelines parse LLM output into motor primitives, combining the flexibility of neural networks with the logical clarity of symbolic reasoning. Research from the University of California, Berkeley and MIT has advanced both approaches significantly over the past three years.
Sim-to-Real Transfer
Collecting real-world robot data is expensive. A robot must physically perform a task hundreds of times to learn from it. Simulation offers a way around this. Robots can be trained in virtual environments at scale, at low cost, without risk of physical damage.
The challenge is the reality gap. A policy trained in a perfect simulation often fails when deployed on a physical robot. Virtual objects have ideal textures. Virtual friction is exact. Virtual sensors have no noise. The real world is messier by definition.
Domain randomization addresses this partially. During simulation, parameters like friction, lighting, object mass, and camera noise are varied randomly. The robot learns to handle variance. When it encounters a real environment, it has already seen many variations. This approach, pioneered by researchers at OpenAI and UC Berkeley, has become a standard tool in the roboticist's toolkit.
By 2026, most commercial deployments use sim pre-training followed by minimal real-world fine-tuning. Companies like Covariant and Figure AI have built pipelines where robots learn in simulation and then adapt online to specific warehouse environments. The reality gap has not been closed, but it has been narrowed enough for commercial viability.
Reward Modeling with LLMs
Classical reinforcement learning requires a reward function. This function tells the robot how well it is doing. Designing reward functions is notoriously difficult. Hand-crafted rewards often produce behaviors that technically satisfy the metric but fail in practice. A robot told to maximize "distance to target" might simply move the target closer to itself — a problem researchers call reward hacking.
LLMs offer an alternative. An LLM can evaluate whether a robot's action advanced the task goal. After each action, the model judges whether the action was reasonable given the current state. This provides a dense, semantic reward signal without manual engineering.
This approach, sometimes called LLM-as-judge, is particularly powerful for long-horizon tasks. The robot receives language feedback at each step. It knows not just that it failed, but why. It can course-correct rather than blindly optimizing a proxy metric. Research from Stanford's IRIS group and DeepMind has demonstrated this approach on tasks requiring 50 or more sequential steps.
Memory and Long-Horizon Planning
A robot executing a complex task must remember what it has already done. It must maintain a model of the current world state. It must replan when something goes wrong.
LLMs with large context windows solve part of this problem. Modern models can process over 200,000 tokens. This is enough to maintain a detailed task history as part of the prompt. The robot's previous actions are included. The current scene description is included. The LLM regenerates its plan from this updated context.
This leads to hierarchical planning. The LLM generates a high-level task graph. A lower-level controller executes each node in the graph. If a node fails, the LLM is re-prompted with the updated state. It generates a recovery plan. This two-level architecture separates slow reasoning from fast control — a design principle borrowed from cognitive science.
Frameworks like Google's "SayCan" and the follow-up SKIT system use language as the planning representation. The robot says what it plans to do. It checks whether its actions match the plan. If they do not, it re-reasons. This interpretable loop is critical for safety-critical applications where engineers and regulators need to understand why a robot made a decision.
Leading Embodied AI Systems in 2026
The gap between research demos and commercial products has narrowed significantly. Several platforms are now operating in real environments with documented performance data.
Figure 01 (from Figure AI) is one of the most visible. This humanoid robot is deployed at a BMW manufacturing facility in South Carolina. Workers can give it natural-language instructions. The robot uses a VLM to understand its surroundings. It can hand tools to assembly workers. It can sort parts. Figure AI raised over $675 million in its most recent funding round and was valued at approximately $2.6 billion as of early 2026, according to reporting by Reuters and The Verge.
Tesla Optimus uses Tesla's existing full self-driving computer vision infrastructure combined with a custom actuator control system. Its bipedal design is intended for factory floor tasks. Tesla has deployed prototype units in its own facilities. The company's stated target is broader deployment within Tesla operations by late 2026, though industry analysts note that timeline remains ambitious.
1X Technologies NEO gamma is designed for home assistance. It is lighter than most industrial humanoids, prioritizing safe operation near people. Backed by OpenAI, it is in beta testing in Scandinavian eldercare facilities. Its target use case is helping elderly individuals remain independent at home — a market that is growing rapidly as populations age across developed economies.
Google DeepMind's RoboAgent is primarily a research platform. It demonstrated multi-task generalization across 38 distinct skills using the RT-2 architecture. Results were published in peer-reviewed journals including Science Robotics. The platform is not a commercial product, but its research findings directly inform commercial systems across the industry.
Stanford Mobile ALOHA is an open-source robot that cost less than $32,000 to build. It uses imitation learning. A human teleoperates the robot for 50 demonstrations of a task. The robot learns to replicate the task from those demonstrations. It can cook, clean, water plants, and fold laundry. Its low cost and open-source design have made it a widely adopted research and education platform within the academic robotics community.

Real-World Applications Taking Off
Industrial and commercial adoption is accelerating across multiple sectors, with measurable impact on operational efficiency.
Warehouse and logistics remain the largest commercial market for embodied AI today. Amazon has deployed more than 750,000 robots across its fulfillment network. Covariant's AI picking system handles over 100,000 stock-keeping units. By 2026, fulfillment centers using VLM-powered robots achieve picking speeds approaching human levels for the first time in the industry's history.
Healthcare and eldercare are growing rapidly as deployment environments. Diligent Robotics' Moxi robot assists nurses in hospitals across the United States. It delivers supplies. It retrieves charts. It reduces the administrative burden on clinical staff so nurses can focus on patient care. Meanwhile, 1X NEO is entering Scandinavian eldercare homes following successful pilot programs. Surgical systems like the Da Vinci platform are incorporating LLM-powered voice command and procedure narration, allowing surgeons to direct the robot verbally during procedures.
Home robotics is beginning to incorporate language understanding at scale. iRobot, Roborock, and newer entrants are adding LLM-based natural-language interfaces. Instead of programming a cleaning schedule, users can say "clean under the dining table after dinner." The robot interprets the instruction using its VLM and executes accordingly. This shift from scheduled automation to instruction-based interaction represents a meaningful change in how consumers relate to home robots.
Space exploration presents a compelling use case for embodied AI. NASA's Valkyrie robot, enhanced with LLM-based reasoning, is being tested for Mars habitat maintenance tasks at the Johnson Space Center. Communication delays between Earth and Mars can exceed 20 minutes each way, making real-time teleoperation impractical for many tasks. Language-based instruction from Earth allows astronauts to direct robots without the need for precise teleoperation, enabling continuous habitat maintenance during crew activity.
Agriculture is another emerging vertical. Robots using VLMs can identify crop health from visual symptoms, selectively harvest ripe produce, and navigate unstructured outdoor terrain without pre-mapped paths. Early deployments in California and the Netherlands have demonstrated meaningful reductions in labor costs for specialty crop harvesting.
Open Challenges and What Comes Next
Honest assessment matters. Embodied AI is advancing rapidly, but significant problems remain unsolved. Readers evaluating this space deserve a clear picture of what is real versus what is aspirational.
Latency is the most immediate technical bottleneck. A VLM inference can take hundreds of milliseconds on current hardware. A robot reacting to a moving obstacle needs to respond in under 100 milliseconds. Closing this gap requires hardware acceleration at the edge. Custom AI accelerators, edge GPUs, and model quantization are all part of the active solution. Companies including NVIDIA, Intel, and a cohort of AI chip startups are racing to solve this problem. No complete solution exists yet.
Generalization is the deeper problem. Robots perform well on tasks and environments similar to their training data. They degrade sharply when confronted with truly novel objects or layouts. A robot that can sort boxes in one warehouse may fail entirely in another with different lighting and box materials. "Open-world" robustness — the ability to handle anything the real world presents — remains an active research problem with no solved path in sight.
Data scarcity compounds this challenge. Text data for LLMs comes from the internet at internet scale. Robot demonstration data must be collected by physically operating robots. The best publicly available robot datasets contain fewer than one million demonstrations. Internet text corpora contain trillions of tokens. This asymmetry limits how quickly robot foundation models can improve relative to language models.
Safety in unstructured human environments requires real-time risk assessment that current systems cannot reliably provide. A robot working alongside humans cannot wait for a cloud inference round-trip. It cannot make mistakes that endanger people. Current validation frameworks are inadequate for the complexity of dynamic, multi-agent environments. Regulators in the European Union and United States are actively developing new standards for human-robot collaboration, but these frameworks are still years from finalization.
Energy and compute present a practical constraint that affects deployment economics. VLMs are large and power-hungry. A robot running a state-of-the-art VLM requires significant cooling and battery capacity. Smaller, specialized models for on-robot deployment are an active area of development at multiple companies. The trade-off between model capability and power consumption remains unsolved.
Looking ahead, the trajectory is clear. By 2030, limited commercial household humanoid assistants are likely to be available in some form. True human-level generalization across novel tasks — robots that adapt like humans without months of retraining — remains a harder problem that may take longer to solve. The next breakthroughs will likely come from sample-efficient learning methods, improved safety frameworks, and more capable edge computing hardware.
Conclusion
Embodied AI is the convergence point of three AI revolutions: vision, language, and action. Foundation models trained on internet-scale data have given robots the common sense they previously lacked. Vision-language models have given them the ability to perceive and reason about open-ended real-world scenes. The combination is enabling a new generation of robots that can follow instructions, adapt to new situations, and operate outside of carefully controlled factory cells.
The year 2026 represents a genuine inflection point. Commercial deployments are outpacing research skepticism. Engineers entering this space now have the opportunity to shape the next decade of human-machine interaction.
The central unsolved problem remains generalization. Robots that can adapt the way humans do — handling novel tasks without months of retraining — do not yet exist in any commercial form. But the path toward them is visible. The key research groups are funded. The commercial deployments are generating real-world data. And for the first time, the gap feels closable.
For those following this space, the teams to watch include DeepMind Robotics, Carnegie Mellon's Robot Learning Lab, Figure AI, and the broader open-source embodied AI community built around platforms like Mobile ALOHA. The pace of progress has been remarkable. There is every reason to believe it will continue.