Real-Time Learning: How RAG Systems Stay Updated Without Retraining
Traditional RAG pipelines index a snapshot of your knowledge base. This guide covers four architectural approaches to keeping retrieval current without retraining.
Introduction
Picture a customer support chatbot powered by retrieval-augmented generation. The underlying LLM is solid. The retrieval pipeline returns contextually relevant chunks. Everything works — until your product team pushes a pricing update. Three days later, the bot is still recommending old prices. That's the real-time RAG problem in a nutshell.
Traditional RAG pipelines index a snapshot of your knowledge base at a point in time. New data means new indexing jobs. Updated facts mean re-embedding everything. Deleted content requires cleanup you may not have automated. The model weights are frozen, but so is the knowledge the system can retrieve.
RAG without retraining is not about changing what the LLM knows. It's about keeping the retrieved context current — without rebuilding the entire retrieval layer each time the underlying data changes. This article covers four architectural approaches that production teams use to solve this problem, ranging from incremental index updates to direct knowledge injection at inference time.
Why Static Snapshots Break Production RAG
A conventional RAG pipeline follows a predictable sequence. You ingest documents, split them into chunks, generate vector embeddings for each chunk, and store those embeddings in a vector database. That database is a snapshot. It does not automatically know when a product description changes, when a policy gets updated, or when a new knowledge base article goes live.
The failure modes are concrete. An outdated retrieved context can make an LLM confidently wrong — a phenomenon sometimes called hallucination from stale data. For time-sensitive queries about pricing, availability, or regulatory policy, stale retrieval is not just unhelpful; it can be harmful. And if you try to solve it by running full re-indexing jobs every night, you're burning GPU compute on a task that should not require a full rebuild.
Let's be specific about the cost. Re-indexing 1 million text chunks — generating fresh embeddings for every piece of content — typically takes hours on a modest GPU cluster and incurs meaningful API or infrastructure costs. For a large enterprise knowledge base with millions of documents, this is not a trivial operation. The goal of real-time RAG is to eliminate or dramatically reduce this overhead by updating only what changed.
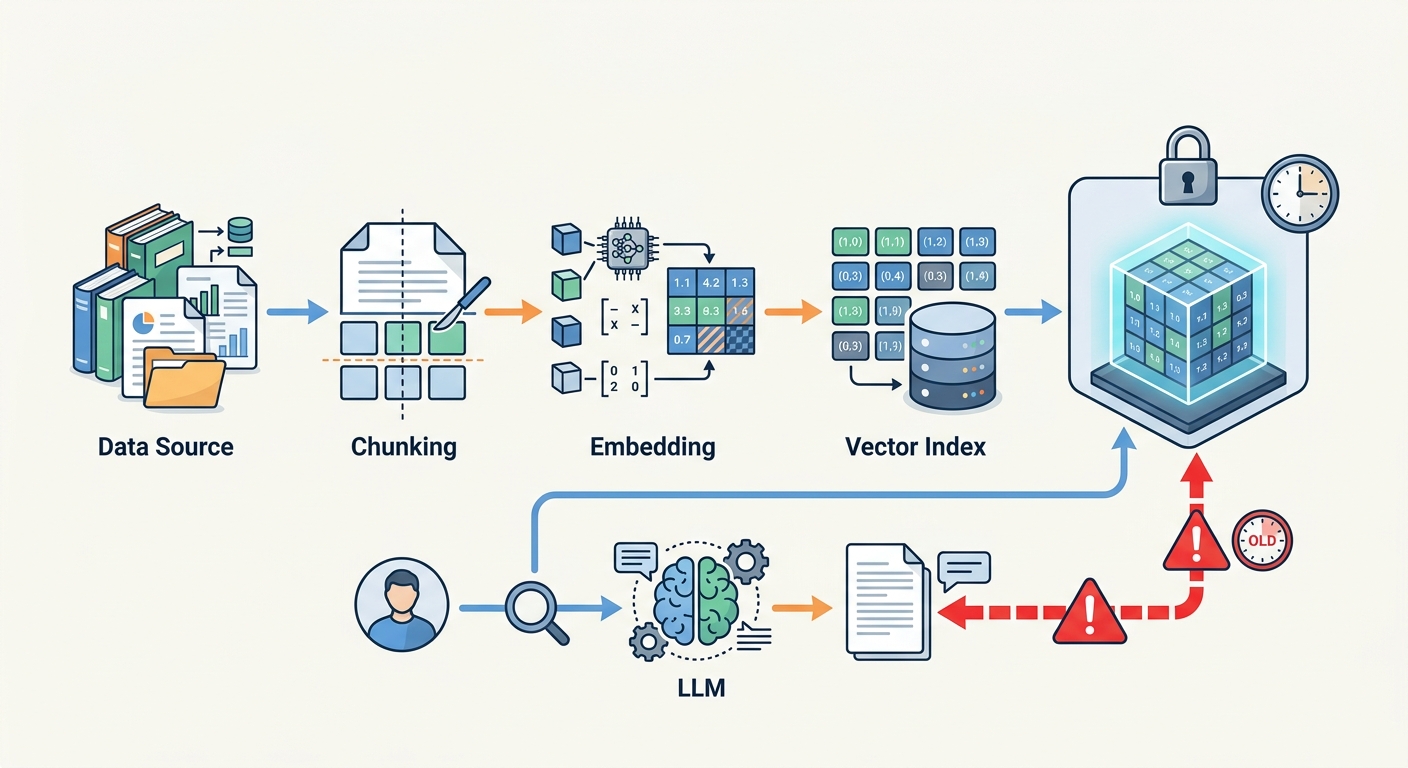
Approach 1: Incremental and Hybrid Indexing
The most direct solution is to stop rebuilding the whole index and instead update only the parts that changed. Incremental indexing is exactly what it sounds like: new documents get new embeddings that are appended to the existing index, changed documents get their old chunks marked as invalid and new chunks added, and deleted documents get soft-deleted using metadata filters.
Modern vector databases are built to support this workflow. Pinecone, Weaviate, and Qdrant all expose upsert operations that let you add or update individual vectors without touching the rest of the index. You can attach metadata to each chunk — creation date, version number, document ID — and filter on that metadata at query time to exclude stale entries. When a document is updated, you do not delete the old chunk; you add a new version with a higher version number and filter for version = MAX in your queries.
This approach works particularly well for document repositories that receive frequent additions or corrections. A legal document management system, a technical documentation wiki, or a content library with regular publishes all fit this pattern naturally.
The tradeoff is that your query logic must be more sophisticated. You need to filter out stale chunks at retrieval time, which adds a small latency overhead and requires your application layer to track chunk versions correctly. Index size can also grow over time if you rely only on soft deletes and never compact the index, so periodic compaction jobs are recommended even with incremental indexing.
Approach 2: Cache-Aside Retrieval
Not all knowledge lives in documents. A growing share of enterprise RAG systems retrieve context from structured data sources — product catalogs in PostgreSQL, pricing tables in MySQL, inventory data from internal APIs. For this data, incremental indexing is the wrong tool. What you want is cache-aside retrieval.
The architecture is straightforward. Your authoritative data lives in a live database or key-value store that is updated in real time by your application. When a RAG query comes in, you first check that live store for exact matches by document ID, customer ID, product ID, or whatever natural key fits your domain. On a hit, you get fresh data immediately. On a miss, you fall back to your vector database for semantic search across unstructured content.
Redis is a popular choice for the fast live layer because it offers sub-millisecond read latency and supports TTL-based expiration, which gives you automatic staleness control. You can also use PostgreSQL with a read replica close to your retrieval tier. The key design decision is choosing an appropriate TTL: too short and you overload your live store with redundant queries; too long and you reintroduce the staleness problem you were trying to solve.
This approach requires no re-indexing at all for structured data. When a product price changes in your catalog, the change is immediately visible in your live store and therefore in your next retrieval. and a retrieval cache gives you sub-millisecond latency for high-frequency queries. The limitation is that it only works for data with a natural key dimension. Pure prose documents without structured identifiers do not fit this pattern — for those, you still need your vector index.
Approach 3: Knowledge Patch Injection
Sometimes the freshest information does not live in your document store or your structured database. Sometimes it comes from a live API call — a real-time inventory count, the current exchange rate, today's support ticket status. Knowledge patch injection is a technique that brings this live data directly into the prompt at inference time, without any changes to your index.
The mechanism works like this. Before sending a query to your LLM, your system identifies the time-sensitive facts that are relevant to the user's question. You fetch those facts from their source — an API, a database, a real-time feed. Then you prepend them to the prompt as a context block with a clear attribution header: "As of June 2026, the following information is current..." The LLM reads both the freshly injected facts and the chunks retrieved from your vector index. If there is a conflict between the patch and the retrieved context, the model generally privileges the most recent information, especially when the patch is framed explicitly.
LangChain supports this pattern through its RunnableParallel construct, which lets you fetch context from multiple sources in parallel before constructing the final prompt. LlamaIndex offers a ContextChatEngine with custom node injectors that can splice live data nodes into the retrieval context tree. The advantage is immediacy: you can update your prompt's context on every single query without rebuilding anything. The risk is prompt length. Most LLMs have finite context windows, and you must prioritize which facts to inject when you cannot include everything.
Approach 4: User Feedback and Weighting Loops
The three approaches above address knowledge that changes in external systems. But real-time learning also means learning from your users. Feedback weighting loops give your RAG system a form of experience — the ability to improve its retrieval quality over time based on signals from actual usage.
The signals can be explicit or implicit. Explicit signals are thumbs-up or thumbs-down ratings on individual answers, correction prompts where a user tells the system the answer was wrong, or follow-up questions that imply dissatisfaction with the initial response. Implicit signals include session abandonment, time-to-clarification — how long it takes a user to get a satisfactory answer — and click-through on source citations if your system surfaces them.
The implementation is straightforward in principle. You attach a quality score and a freshness timestamp to each chunk in your retrieval index. When a chunk produces a positively rated answer, you increment its quality score. When a chunk is associated with a negative rating or a correction, you decrement it. At query time, you boost chunks with higher quality scores and penalize those with poor track records. This means user feedback actively re-weights your retrieved chunks over time, without touching the underlying model.
More sophisticated implementations use these signals to retrain lightweight chunk relevance models — not the LLM itself, but a smaller retrieval reranker or a gradient-boosted model that predicts chunk utility from features including quality score, age, and semantic similarity. Tools like Ray Serve make it practical to serve these lightweight models alongside your retrieval pipeline. Even simpler systems can achieve meaningful improvements with a SQL-backed scoring table and a cron job that recalculates weights nightly.
Decision Framework: Choosing the Right Approach
Most production systems do not rely on a single approach. The right strategy depends on the structure of your data and the frequency of your updates. Use this as a starting point for your evaluation.
If your data is primarily unstructured documents and updates arrive as new files or document revisions, incremental indexing is your foundation. Append new embeddings, track versions, filter stale chunks. If your data is structured with natural keys — product IDs, account numbers, policy codes — cache-aside retrieval gives you zero-latency updates without any index changes. If your most critical facts come from live APIs or third-party feeds that you cannot control, knowledge patch injection lets you bring that data in at query time without any infrastructure modification.
In practice, the most resilient production systems layer these approaches. They use cache-aside for structured data, incremental indexing for documents, and knowledge patches for the handful of genuinely real-time facts that matter most. A single monolithic approach rarely covers all the cases you will encounter.
Production Gotchas and Open Problems
Even when you have chosen the right architecture, real-time RAG surfaces challenges that are easy to underestimate.
Version skew is a common failure mode. If some of your chunks reflect old policy and others reflect new policy, the LLM may reason over contradictory context and produce inconsistent answers. You need explicit conflict resolution — either by forcing a temporal filter that excludes old chunks when new ones are available, or by structuring your context injection to clearly mark which information is authoritative.
Key insight — Version skew is the leading cause of RAG hallucinations in production. Temporal metadata filtering is not optional; it is the minimum viable solution.
Embedding drift is subtler. As your data distribution shifts — new topics, new terminology, new product names — the embeddings you generated six months ago may no longer cluster correctly with the current corpus. Periodic re-embedding of high-value or frequently retrieved chunks can help, but it reintroduces some of the compute cost you were trying to avoid.
Latency is another constraint. Every real-time update mechanism adds per-query overhead: filtering metadata, fetching from a live store, or injecting a knowledge patch takes time. Set explicit latency budgets and instrument each layer so you know where your retrieval time is going.
Finally, evaluation is genuinely hard. Accuracy is straightforward to measure — you have ground-truth questions and answers. But measuring freshness is not. There is no standard benchmark for "how up-to-date is your RAG system." You have to define that for your domain and build custom evaluation datasets.
Expert Q&A
Q1: How does incremental indexing differ from full re-indexing in a RAG pipeline?
Full re-indexing regenerates vector embeddings for every chunk in your knowledge base — a process that can take hours on large corpora and consumes significant GPU resources. Incremental indexing appends or updates only the vectors for chunks that have changed: new documents get new embeddings appended to the existing index, updated documents get new versioned chunks added alongside old ones, and deleted documents are soft-deleted via metadata filters. The vector database itself is not rebuilt; only the affected entries change. This dramatically reduces compute cost and eliminates the downtime window that full re-indexing requires.
Q2: What is the difference between cache-aside retrieval and a retrieval cache in a RAG context?
A retrieval cache stores the results of recent queries to serve identical or near-identical requests faster on subsequent hits. Cache-aside retrieval, by contrast, is a data access pattern where a fast live store — typically a key-value database like Redis or a read replica of PostgreSQL — serves as the authoritative source for structured data, while the vector database handles semantic search over unstructured content. Cache-aside serves fresh data directly from a live system that is updated in real time by your application. A retrieval cache serves previously computed results; it does not independently source new information. In practice, cache-aside and retrieval caching are often used together: the retrieval cache speeds repeated vector queries, and the cache-aside layer provides fresh structured data.
Q3: How does knowledge patch injection avoid the staleness problem without modifying the vector index?
Knowledge patch injection fetches time-sensitive facts from their live source — an API, database, or real-time feed — at the moment a query is made, and prepends those facts directly to the prompt context. Because the freshest information is injected into the prompt itself, the system retrieves up-to-date facts even if the vector index contains stale chunks from the same topic. The update latency is effectively zero — the data changes in the source system and the next query automatically sees the new values. This approach requires no index changes, no re-encoding, and no re-indexing jobs. The limitation is prompt context length: you cannot inject unlimited facts, so you must prioritize which information is most critical for each query.
Q4: Can a RAG system actually "learn" from user feedback without retraining the LLM?
Yes — but "learning" in this context means re-weighting or re-ranking retrieved chunks, not updating model weights. A feedback weighting loop attaches quality scores to individual chunks based on explicit signals like thumbs-up/down ratings or implicit signals like session abandonment and correction prompts. Positively rated chunks get boosted in future retrieval; negatively rated ones get penalized. More advanced implementations train a lightweight reranker — a small gradient-boosted model or linear classifier — on features derived from these signals. This is online learning applied to the retrieval layer, not the generation layer. The LLM itself never changes, but the chunks it sees become better over time based on real usage patterns.
Q5: What is embedding drift and why does it threaten real-time RAG systems?
Embedding drift occurs when the semantic distribution of your knowledge base shifts over time — new product names, updated terminology, new subject matter — but the embeddings were generated against the old distribution. Old embeddings may no longer cluster correctly with semantically related content in the current corpus, which degrades retrieval accuracy even if the chunks themselves are up to date. In a real-time RAG system that updates its index incrementally but never re-embeds old chunks, drift accumulates gradually and silently. The symptom is a slow, unexplained decline in retrieval quality that is not tied to any specific data update. Mitigation strategies include periodic re-embedding of high-value or high-traffic chunks, monitoring retrieval precision over time, and using hybrid search (dense + sparse vectors) to reduce dependence on embedding quality alone.
Conclusion
Real-time RAG is not a single technique — it is a set of architectural decisions that keep your retrieval layer current without forcing you to retrain your LLM or rebuild your entire index on every data change. Incremental indexing handles new and changed documents. Cache-aside retrieval brings in live structured data. Knowledge patch injection lets you inject the freshest facts at query time. Feedback weighting loops let the system learn from its users.
The right combination for your system depends on what your data looks like and how often it changes. Start by auditing your data sources and update patterns. Then pick the approach that matches your most critical data type. Most teams end up layering multiple strategies, and that is the correct instinct.
Subscribe to the Algorithmine newsletter for more guides on RAG architecture, LLM infrastructure, and production AI systems.