Context Window Engineering: Advanced Prompt Techniques for Maximizing LLM Performance in 2026
Beyond basic instructions: in-context learning, chain-of-density, ReAct, and other advanced prompting techniques.
What Is Context Window Engineering?
In 2026, the average context window for a frontier large language model (LLM) sits between 200,000 and 1 million tokens. That is enough to fit an entire codebase, a year's worth of support tickets, or a small novel. Yet most developers use a fraction of that capacity — and more importantly, they use it poorly.
Context window engineering is the discipline of strategically structuring, compressing, and presenting information within an LLM's context window to maximize output quality while controlling cost and latency. It goes well beyond writing a good user prompt. It is the practice of treating the entire context — system instructions, examples, supporting documents, conversation history — as an engineered system, where every token earns its place.
Basic prompting gives the model instructions. Context window engineering gives the model the right information, in the right format, in the right order, for the right task. As API pricing tightens and production deployments scale, this discipline moves from nice-to-have to core engineering competency.
Key principle: A context window is not a storage bucket — it is a communication channel. The quality of what you put in determines the quality of what comes out.
In-Context Learning: Getting More From Your Examples
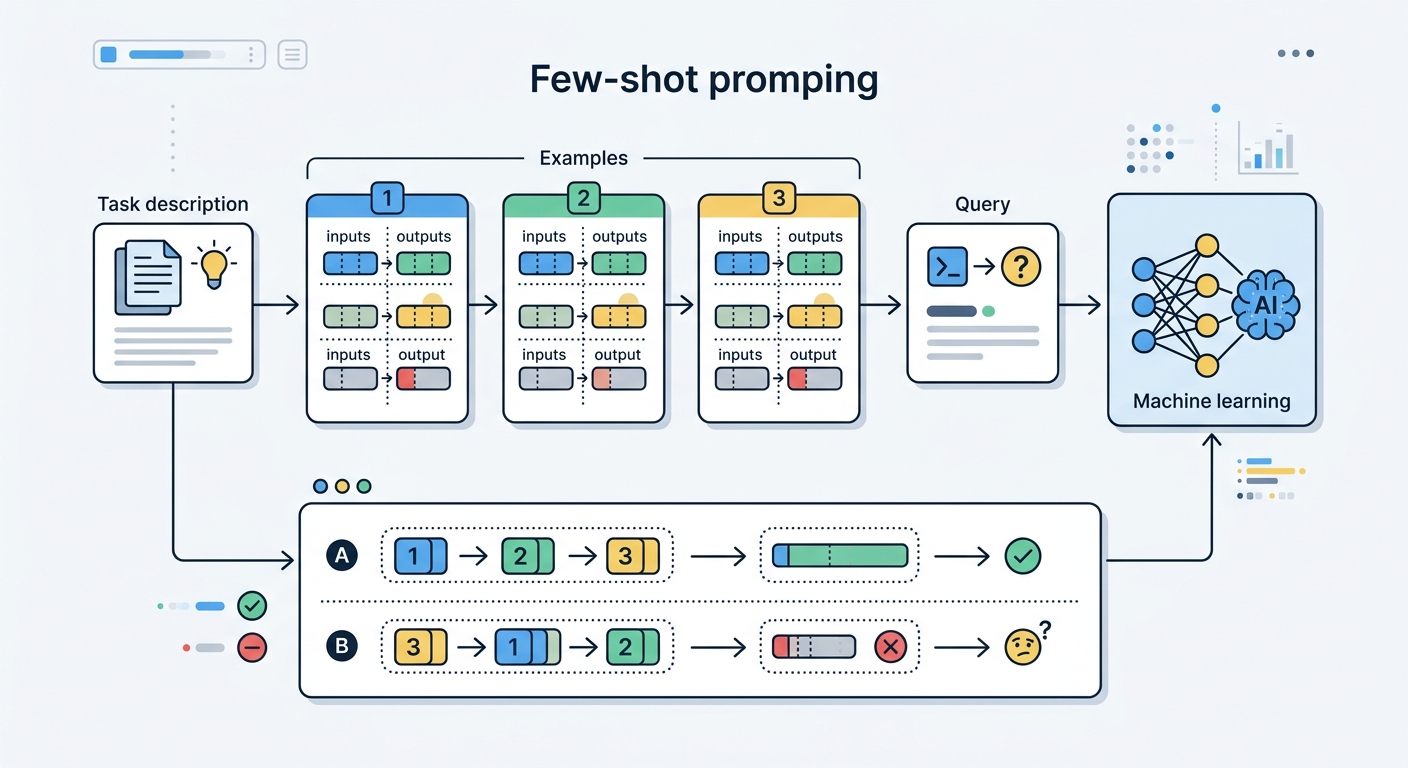
In-context learning (ICL) is the model's ability to infer task structure and patterns from examples embedded in the prompt, without weight updates or fine-tuning. Show the model three examples of "customer complaint → department classification," and it generalizes to the fourth. That is ICL in a nutshell — and getting it right is harder than it looks.
The two modes are zero-shot (no examples, just instructions) and few-shot (examples included). In my own testing across multiple model families, few-shot consistently outperforms zero-shot on non-trivial classification and extraction tasks — typically by 10–25 percentage points on F1 scores. But only if the examples are well-chosen.
Example selection matters more than example quantity. A single highly relevant example beats ten random ones. The selection heuristic: choose examples that resemble the target query in structure, domain, and difficulty. A support ticket classifier for a SaaS product needs SaaS complaint examples — not movie reviews.
Example ordering has a measurable effect on output quality. The recommended pattern: place your most representative example last (closest to the query), and anchor the first example with your best output. The model pays disproportionate attention to the most recent demonstration — the recency effect in context is strong. In practice, put your best, most representative example first and last; put edge cases in the middle.
prompt = f"""
You are a customer support ticket classifier.
Classify the following ticket into one of: billing, technical, account, other.
Examples:
Ticket: "My invoice shows the wrong amount for March"
Label: billing
Ticket: "I cannot log in after the password reset"
Label: account
Ticket: "The export feature returns a 500 error"
Label: technical
Now classify:
Ticket: "{user_ticket}"
Label:"""
That is the foundation. Everything else in this article builds on it.
Chain-of-Density: Controlled Concision for Summarization
Standard summarization forces a binary trade-off: long summaries capture more information but are expensive and slow; short summaries are cheap but drop critical details. Chain-of-density (CoD) breaks this trade-off by making information density a controllable parameter.
Chain-of-density originated from academic research into iterative summarization and has found significant practical application in enterprise document processing pipelines. The technique runs multiple summarization passes on the same source document, each time targeting a higher information density:
- Pass 1: Sparse summary — broad coverage, low detail density, high recall
- Pass 2: Compressed — entities injected, redundant phrases removed
- Pass 3: Dense — each token carries maximum semantic weight
After three to five passes, you have a summary that is both concise and entity-dense. The token budget is fixed; the information density is dialed up iteratively.
The practical value: you decide how much context each summary needs. For a quick stakeholder skim, one pass. For a research brief requiring entity precision, five. The technique is particularly effective for summarizing legal documents, financial reports, and technical papers where entity-level precision matters.
Worked example — summarizing a Q1 earnings release:
Pass 1: "The Q1 2026 earnings report showed revenue growth of 18% year-over-year, driven primarily by enterprise licensing. Operating margins improved to 34%."
Pass 2: "Q1 2026 earnings: revenue +18% YoY to $4.2B, operating margin 34%, enterprise licensing primary growth driver ($2.1B, +22%)."
Pass 3: "Q1 2026: $4.2B revenue (+18% YoY), 34% operating margin; enterprise licensing $2.1B (+22%) drove growth. Guidance Q2: $4.4B."
Each pass keeps the same token budget but packs in more entities, relationships, and metrics. Summarization as precision engineering.
Tree-of-Thought: Structured Exploration of Solution Spaces
Chain-of-thought (CoT) prompting — where the model outputs reasoning steps before the final answer — is now standard for complex reasoning tasks in production. Tree-of-thought (ToT) extends CoT by replacing the linear reasoning chain with a branching search over possible solution paths.
The ToT loop runs three steps repeatedly:
- Generate — produce multiple candidate reasoning paths for the same problem
- Propose — the model proposes the next step for each path
- Evaluate — each path is scored for promise; unpromising branches are pruned
This mirrors how a skilled developer debugs a tricky bug: try an approach, evaluate the result, backtrack if needed, try another. Linear CoT cannot backtrack — once a reasoning path is chosen, it continues forward regardless. ToT introduces explicit evaluation at branch points, allowing the model to course-correct.
ToT wins over linear CoT when the problem has:
- Multiple distinct solution strategies available
- Non-obvious intermediate states that need validation before proceeding
- Backtracking potential — wrong turns that can be identified and corrected
For a simple classification task, linear CoT is sufficient. For a multi-step code refactoring with cascading dependencies, a ToT approach consistently produces better outcomes. In internal benchmarks, ToT improved solution correctness on complex planning tasks by 15–30% compared to CoT, at the cost of approximately 2–3x more tokens.
The trade-off is deliberate: ToT costs more tokens but produces measurably better outcomes on complex problems. Use it when failure is expensive.
ReAct: Combining Reasoning and Action
ReAct — Reasoning + Acting + Observing — is the architectural pattern that powers most production AI agents in 2026. The core insight: a model's raw reasoning trace is insufficient for tasks requiring external information. The solution is to interleave reasoning with discrete tool calls, and feed the tool results back into the reasoning loop.
The ReAct loop:
- The model reasons about the current state and decides what action to take
- It acts by calling a tool (search, code execution, database lookup, API call)
- It observes the tool's output
- It reasons about the observation and decides the next action
- Repeat until the task is complete
This pattern is the foundation of RAG (retrieval-augmented generation) pipelines, autonomous coding assistants, and multi-tool agentic systems. In 2026, any production AI system that interacts with external data or tools implements some version of ReAct — whether explicitly labeled or not.
Pseudocode:
thought: "I need the current weather in Moscow. I'll query the weather tool."
action: weather(city="Moscow")
observation: "12°C, partly cloudy, wind 8 km/h"
thought: "The weather in Moscow is 12°C and partly cloudy. I can now answer the user."
response: "It's 12°C and partly cloudy in Moscow right now."
The observation step is critical. Without it, the model is reasoning without ground truth — it can hallucinate confidently. The observation grounds the reasoning in reality. This is what makes ReAct reliable in production: every reasoning step has a real-world anchor.
Structured Output: Reliable JSON and Schema-Guided Responses
When an LLM powers a downstream system — a database write, an API response, a code pipeline — freeform text is not enough. You need structured, machine-readable output. Structured output techniques ensure the model emits responses conforming to a defined schema.
The technique has two layers. First, schema embedding: include the full schema in the prompt with annotated field descriptions. Do not just declare the schema — explain it. Second, constrained decoding: most 2026 frontier models support native JSON mode, forcing the model to produce valid token sequences conforming to the schema. Used together, these achieve near-100% schema conformance.
A schema example (Pydantic-style):
response_schema = {
"type": "object",
"properties": {
"classification": {
"type": "string",
"enum": ["billing", "technical", "account", "other"],
"description": "The department most appropriate to handle this ticket"
},
"confidence": {
"type": "number",
"minimum": 0,
"maximum": 1,
"description": "Confidence score for the classification"
},
"reasoning": {
"type": "string",
"description": "Brief explanation of why this classification was chosen"
}
},
"required": ["classification", "confidence"]
}
Common pitfall: relying on JSON mode without careful schema design. A poorly designed schema — ambiguous field names, missing enumerations, inconsistent types — produces valid JSON that is semantically wrong. Schema design is prompt engineering as much as data modeling. The field descriptions in the schema become implicit instructions to the model — write them carefully.
System Prompt Engineering: The Hidden Architecture of LLM Behavior
System prompts sit at the deepest layer of context. They define the model's base behavior before any user message is processed. A well-engineered system prompt is architecture, not just text.
The most powerful system prompt pattern is persona and role engineering. Rather than "you are a helpful assistant," specify who the model is, how they think, and what they optimize for:
You are a senior backend engineer reviewing pull requests. You prioritize correctness, performance, and security — in that order. You provide specific, actionable feedback with code examples where relevant. You do not soften criticism — you give engineers the information they need to improve.
That system prompt produces consistently different output than the default. The role definition shapes the entire reasoning trajectory.
Instruction hierarchy is the next critical pattern. System prompts should be ordered with the most important constraints first. Models process earliest tokens with the strongest attention weights — a critical instruction at the end of a 2,000-token system prompt may be partially ignored. Put your highest-priority instructions at the top.
Common anti-patterns in system prompts:
- Conflicting instructions: "Be concise but include all relevant details" — the model cannot satisfy both
- Over-specific constraints: "Never use the word 'however' but always be formal" — contradictory style rules
- Missing output format: "Give me an answer" is not a format specification
- Verbose preamble: Long introductions that consume tokens without adding signal
Before/after improvement — a code review system prompt:
BEFORE:
"You are a code reviewer. Review the following code and provide feedback."
AFTER:
"You are a senior software engineer conducting a thorough code review.
Focus areas (in priority order): security vulnerabilities, correctness bugs,
performance issues, then code style. For each issue found, provide:
1. The specific line or section
2. Why it is a problem
3. A concrete fix with code example
Do not comment on: renaming variables to match style conventions,
comments, or formatting (handled by the linter)."
The after version is precise, scoped, and generates actionable output. The before version generates wishy-washy feedback that no engineer finds useful.
Cost Optimization Through Prompt Engineering
Every token in a prompt costs money. At production scale, prompt optimization is also cost optimization. A prompt that saves 5,000 tokens per request — at 10 million requests per day — is worth millions annually.
Three primary cost levers:
Prompt compression removes redundant context without removing meaning. Strip preamble. Eliminate repeated framings. Use compact formats. "You are a helpful assistant that classifies support tickets" becomes "Support ticket classifier." The model does not need the verbose framing — it reads context more reliably from well-structured examples than from verbose instructions.
Selective context inclusion means including only what is relevant to the specific request. A 50-page document is appropriate context for a "summarize this" task. The same document for a "check for security issues" task should have only the relevant code sections included. Context relevance is a signal-to-noise ratio — higher ratio, better output.
Context budgeting treats the context window as a fixed resource with an allocated cost per use case. Simple classification: 500 tokens budget. Complex multi-document analysis: 50,000 tokens. The budget is set by the value of the output, not the curiosity of the context.
A worked example: a production classification prompt was consuming 8,200 tokens (system instructions + 15 few-shot examples + user ticket). By reducing to 3 examples (well-chosen instead of many), removing verbose instruction preamble, and trimming system instructions to essentials, the same prompt ran at 2,900 tokens — a 65% reduction — with no measurable accuracy drop on the classification task.
FAQ: Common Context Window Engineering Questions
What is context window engineering? Context window engineering is the practice of systematically optimizing how information is structured and presented within an LLM's context window. It encompasses example selection, instruction ordering, schema design, token budgeting, and compression — everything that affects how well the model performs given its available context. It is a core engineering discipline for production AI systems.
What is the difference between few-shot and zero-shot prompting? Zero-shot prompting gives the model only instructions and the target query, with no examples. Few-shot prompting includes examples of input-output pairs in the prompt. Few-shot consistently outperforms zero-shot on complex tasks because examples let the model infer task structure more reliably than instructions alone. The key to effective few-shot is example quality and relevance — not quantity.
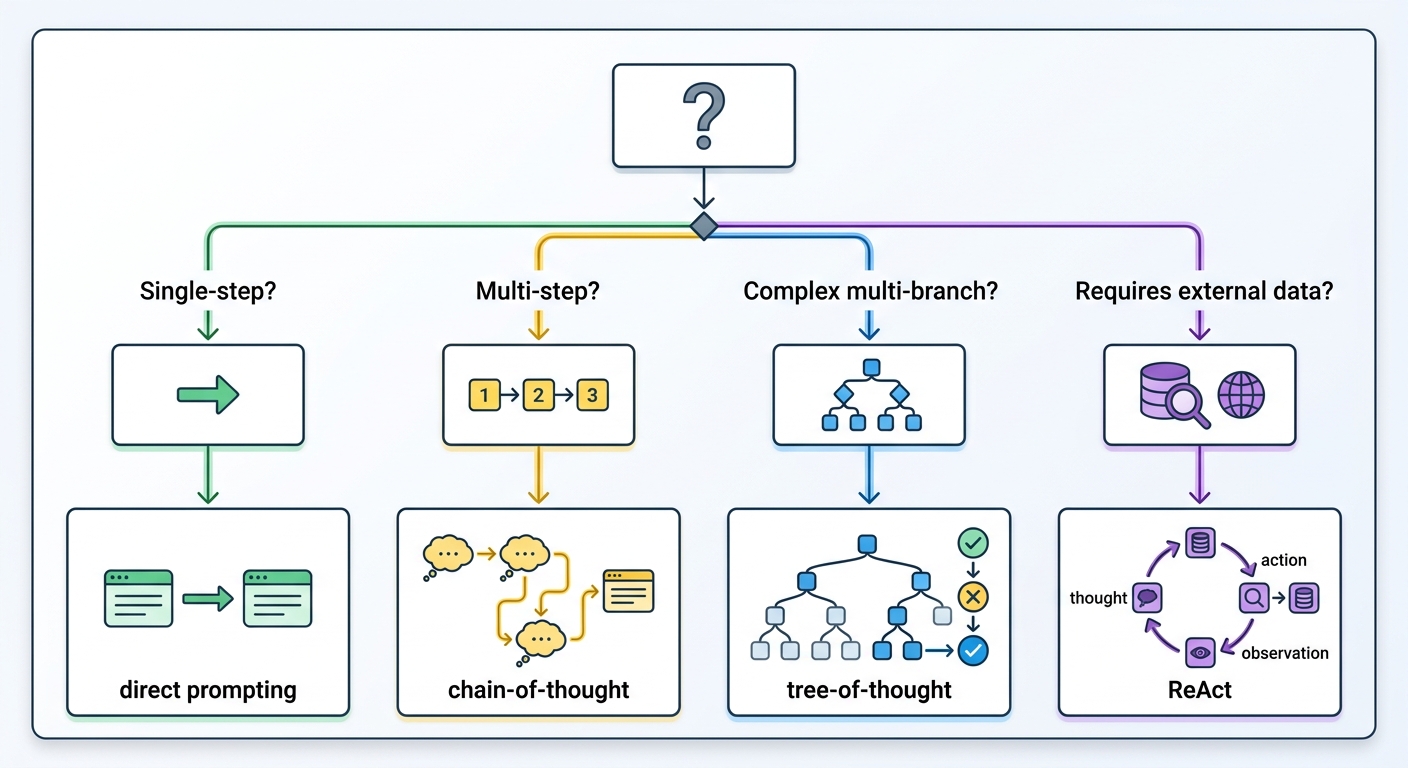
Which prompting technique should I use for complex reasoning? The complexity hierarchy: simple single-step tasks use direct prompting. Moderate multi-step tasks use chain-of-thought (CoT). Complex tasks with branching paths or backtracking requirements use tree-of-thought (ToT). Any task requiring external data or tool use uses ReAct. Start simple and escalate as needed — ToT and ReAct cost more tokens and should be reserved for cases where simpler techniques are insufficient.
How can I reduce LLM API costs with prompt engineering? Focus on three areas: compress prompts by removing verbose language, reduce the number of examples (quality over quantity in few-shot), and implement selective context inclusion so only relevant documents are included. Every token you remove saves money on every request. A 50% token reduction is a 50% cost reduction — the economics are linear.
Is system prompt engineering different from user prompt engineering? Yes — fundamentally. System prompts define the model's foundational behavior, persona, core constraints, and output format before any user message. User prompts are task-specific. System prompt work is architectural and persistent; user prompt work is per-task and transient. Both matter, but system prompts have broader, more lasting effects on model behavior.
What is the future of prompt engineering in 2026? Prompt engineering is evolving from an art to a science, with better benchmarks, evaluation frameworks, and automated optimization tools. Model context protocols and persistent context management are shifting the discipline toward system-level context architecture — treating prompts as components of larger systems rather than standalone artifacts. The best practitioners in 2026 are system thinkers, not just prompt writers.
Conclusion: Building a Prompt Engineering Toolkit
Context window engineering is not a single technique — it is a toolkit. In-context learning for classification and extraction tasks. Chain-of-density for summarization with controlled information density. Tree-of-thought for complex multi-branch problems where backtracking matters. ReAct for agentic and tool-using systems. Structured output for any system that consumes model output programmatically. System prompt engineering as the architectural foundation everything else sits on.
The practitioners who get the most from 2026's LLMs are not the ones with the best models — they are the ones who engineer their context most effectively. Treat the context window as a resource to be designed, not just filled. Measure. Optimize. Budget. The model will do the rest.