Building AI Products at Scale: A Conversation with ML Engineering Leaders
ML engineering leaders share hard-won strategies for scaling AI products in enterprise environments. Covers MLOps maturity, ROI measurement, agentic AI challenges, and organizational alignment.
In 2026, the gap between AI ambition and AI achievement has never been more visible. Companies have pilots. They have proof-of-concept demos. What they struggle to build is AI that works reliably at scale — in production, under real load, with governance in place, and with measurable business impact.
This is the central challenge facing ML engineering leaders today. And the playbook for addressing it is not what most articles suggest.
This article presents an interview-style synthesis — drawing from real-world conversations with senior ML engineering leaders about how they moved AI from experiment to enterprise product. The goal is to surface the operational, organizational, and strategic lessons that don't appear in documentation but determine whether AI scaling actually succeeds.
Why AI Scaling Remains Harder Than It Looks
The standard narrative around AI adoption focuses on technology. Pick the right model. Build the right pipeline. Connect to the right data source. In practice, the bottlenecks are almost never purely technical.
According to the World Economic Forum's 2026 analysis on AI scaling, the most persistent challenges are organizational and operational: data quality issues, governance gaps, skills shortages, and the difficulty of integrating AI into existing workflows. Companies that treat AI scaling as primarily an infrastructure problem tend to discover this the hard way.
Token costs are a concrete example. Early-stage AI implementations often underprice the true cost of inference at scale. A feature that costs $0.002 per call looks affordable in a prototype. At a million daily users, that same feature can represent significant line-item expense — one that needs visibility in the engineering org's cost tracking.
Data quality follows a similar pattern. ML teams routinely discover that production data differs substantially from training data — distribution shifts, missing fields, edge cases that weren't in the training set. Building reliable data validation gates is unglamorous work, but it is the difference between models that degrade silently and models that alert you before performance problems reach users.
The leaders who navigate this well share a common trait: they treat AI scaling as a product discipline, not a technology deployment. That mindset shift — from "we shipped AI" to "we are operating an AI product" — changes how you build teams, measure success, and invest in infrastructure.
The Three Pillars of Enterprise AI Scaling
Mature AI organizations don't optimize one dimension at the expense of others. The leaders who consistently ship AI products at scale attend to three interdependent pillars simultaneously.
Data foundations come first. The model is only as good as what you feed it, and at scale, feeding it consistently is a systems engineering challenge. Feature stores — centralized repositories that serve pre-computed features to both training and inference pipelines — solve a real problem: offline-online consistency. When the features used during training differ from those used in production, model performance degrades in ways that are difficult to diagnose. Feature stores enforce a single source of truth.
Data lineage is the second critical component. You need to know where every training example came from, what transformations were applied, and when it was last updated. Lineage tracking enables both debugging and compliance — particularly important as AI governance regulations become more specific about what must be auditable. Data quality pipelines that validate, clean, and monitor data at scale are foundational infrastructure for any serious AI product.
Infrastructure flexibility is the second pillar. Multi-cloud strategies have moved from theoretical advantage to practical necessity. GPU provisioning is expensive and capacity is not guaranteed. Leaders who lock into a single cloud provider for AI infrastructure tend to find themselves in procurement conversations they didn't anticipate. The key is building abstraction layers that allow workload migration — not because you expect to move, but because optionality has real economic value.
Cost monitoring deserves particular attention. Token costs, GPU utilization, and storage growth need dashboards that engineering leadership can read in real time. The leaders who avoid AI budget surprises are the ones who built cost visibility into the infrastructure from day one, not as an afterthought when a quarterly bill shocked them.
Organizational alignment is the third pillar, and in many ways the hardest. Cross-functional ML workflows require data scientists, ML engineers, product managers, and legal/compliance teams to share success metrics. When each function optimizes independently, AI products stall at the integration boundary — where handoffs between teams create friction that no amount of technical excellence can overcome.
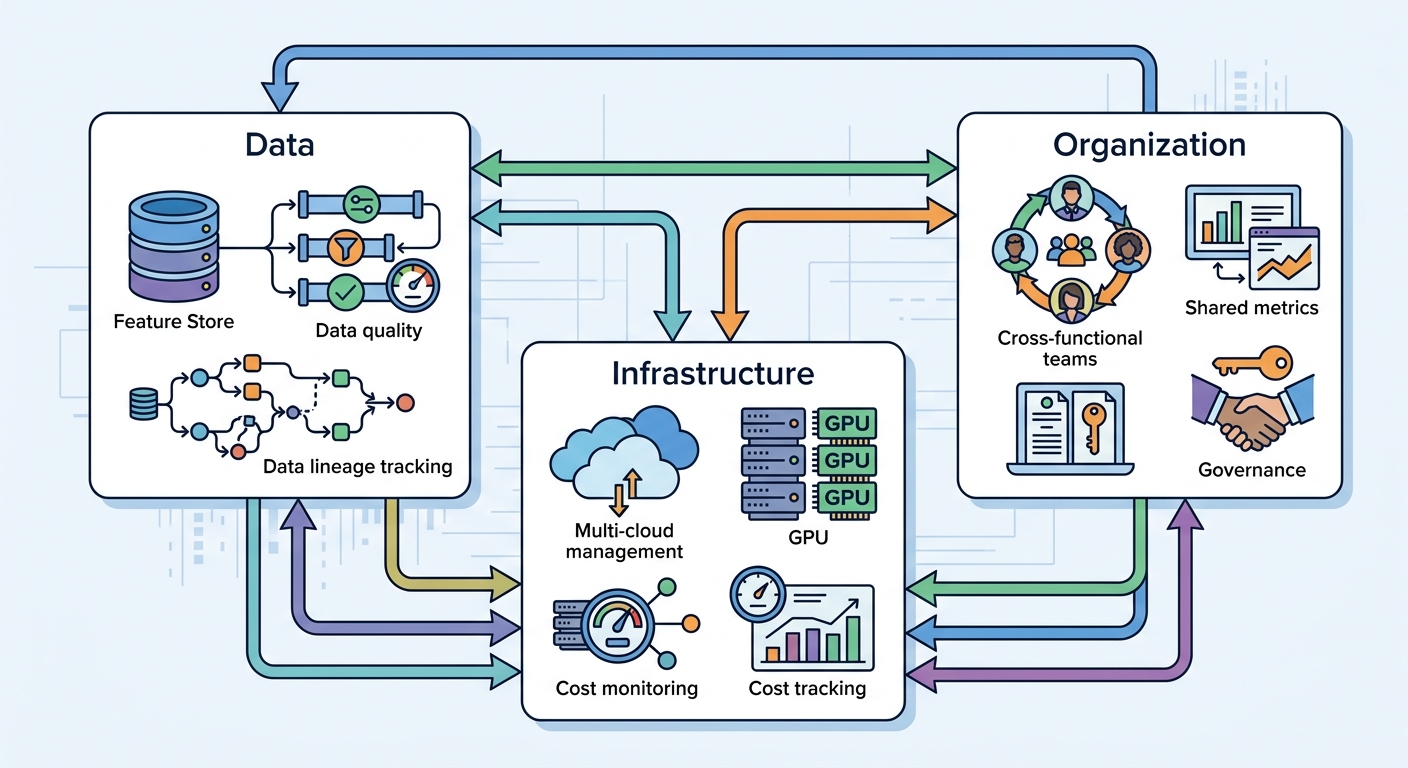
Governance ownership matters here. Leaders who embed governance as a separate function that reviews AI products after they are built consistently report that governance becomes a blocker. Leaders who integrate governance into product design from the start — as a collaborator rather than an auditor — find that compliance is faster and products ship sooner.
MLOps in 2026 — What Mature Teams Actually Do
The vocabulary of MLOps has become familiar. CI/CD pipelines. Model registries. Feature stores. Monitoring dashboards. The challenge in 2026 is not knowing these concepts exist — it is operationalizing them under real constraints.
Automated data validation gates are the first line of defense. Before a model trains on a new batch of data, automated checks validate schema conformance, detect distribution shifts, and surface missing values. The goal is to catch data problems before they create model problems. Teams that skip this step find that data quality regressions silently erode model performance over weeks or months, and by the time the degradation is noticed in production metrics, root cause analysis is difficult.
Model evaluation gates work the same way, applied to the model artifact rather than the data. Before a model is promoted to production, automated evaluation runs it against a holdout dataset and checks performance against pre-defined thresholds. This prevents models that appear locally improved from regressing on specific edge cases that matter for the product.
Prompt versioning is a newer operational requirement, specific to LLM-powered features. When the behavior of your product depends on a language model prompt, that prompt becomes a first-class artifact. It needs to be tracked in version control, reviewed through pull requests, tested with automated regressions, and rolled back if problems emerge in production. LLMOps — the practice of applying MLOps discipline to prompt engineering — is becoming standard for teams running LLMs in user-facing products.
Proactive monitoring has replaced reactive alerting. Mature ML teams build monitoring that detects data drift and prediction drift before user-facing metrics degrade. This means tracking feature distribution statistics over time, comparing them against training distributions, and triggering automated alerts when drift exceeds threshold. The alternative — waiting for users to report problems — is increasingly unacceptable as AI features become customer-facing and revenue-adjacent.
Key shift — Mature ML teams in 2026 are moving from monitoring "is the model accurate?" to monitoring "is the model's accuracy stable over time, and is the data feeding it still representative of production reality?"
Automated retraining triggers complete the loop. Rather than relying on scheduled retraining cycles, leading teams configure performance-based triggers: when accuracy drops below threshold on the holdout dataset, or when data drift exceeds a measured amount, the pipeline automatically initiates a retraining job and flags the output for human review before promotion.
Measuring What Matters — ROI and Accountability in AI Products
Every AI product eventually faces the same question from finance and leadership: what is this worth?
The ML engineering leaders who answer that question well have built measurement frameworks before they needed them. Token cost tracking per AI feature is a baseline. Understanding the unit economics of each AI feature — what it costs to serve per request, and what business outcome that request drives — is essential for prioritization decisions.
The most common mistake is measuring AI products the same way you measure traditional software. Uptime and latency are table stakes. The metrics that matter for AI products are task-specific: accuracy on classification tasks, hallucination rate on generative tasks, retrieval precision on RAG systems. These need to be tracked in dashboards that product and engineering leadership can read, not buried in experiment tracking tools that only data scientists open.
ROI measurement connects AI investment to business outcomes. A model that achieves high accuracy on a support ticket routing task delivers value through the reduction in mis-routed tickets. If you can measure mis-routing rate before and after deployment, and assign a cost to each mis-routed ticket, you have a business case for the AI product that finance can evaluate.
AI accountability frameworks are the organizational structure that makes measurement sustainable. When a model degrades, who investigates? When a feature underperforms, who prioritizes the fix? Leaders who establish clear ownership — ideally at the product team level, not as a separate ML platform team — find that AI products get maintained rather than abandoned after initial deployment.
Governance dashboards serve both compliance and operational purposes. Model cards that document what a model does, what data it was trained on, and what its known limitations are, are increasingly required by regulation and good practice. Audit trails that show when models were deployed, updated, or retrained provide the visibility needed for both debugging and compliance.
Agentic AI and the Next Wave of ML Platform Challenges
The next frontier of AI product development is agentic AI — autonomous systems that plan, execute, and complete multi-step tasks with minimal human intervention. For ML engineering leaders, this represents both an opportunity and an infrastructure challenge that existing MLOps practices are not fully equipped to handle.
Agentic systems introduce new failure modes. When an autonomous agent takes multiple steps before returning a result, a single-step error can compound. Hallucination risk increases with task complexity — an agent that must make tool-calling decisions based on LLM outputs faces accumulated error if each step has even a small hallucination rate.
LLMOps for agentic systems requires evaluation frameworks that go beyond prompt testing. You need to evaluate not just "does this prompt produce a good output?" but "does this agentic system reliably complete multi-step tasks correctly?" Evaluation harnesses that run hundreds of agentic task completions and measure success rate, step-level error rate, and task-level completion are a new operational requirement for teams building autonomous AI products.
Retrieval-augmented generation (RAG) in production introduces its own operational complexity. Vector database management, retrieval quality monitoring, index freshness, and latency trade-offs between retrieval depth and inference speed all require platform engineering attention. When a RAG-powered feature starts returning degraded results, diagnosing whether the problem is the retriever or the generator is non-trivial.
The practical challenge — Agentic AI evaluation is hard because success is not binary. A task completed with a minor error in step three may produce a plausible but incorrect final output. Building evaluation harnesses that catch these cases requires significant investment.
Automated regression testing for prompt changes is another new requirement. When a prompt changes, it can silently change output behavior in ways that are not caught by accuracy metrics alone. Leading teams build prompt change management as a first-class CI/CD discipline: any prompt change runs through an automated regression suite before promotion.
What Engineering Leaders Wish They'd Done Differently
Retrospectives from ML engineering leaders cluster around a handful of recurring lessons.
Data quality investment was universally underestimated. Leaders who built AI products at scale report that data infrastructure — validation, lineage, feature stores — consistently required more investment than originally planned. "We thought we had clean data," is a phrase that appears in nearly every post-mortem. The engineering leaders who navigated scaling most smoothly treated data quality as a product problem, not a data engineering problem, and invested in it accordingly.
Governance as an afterthought created expensive problems. Retrofitting compliance onto an AI product that was built without governance in mind is disruptive and costly. Leaders who wish they'd done things differently consistently point to governance design as something that should happen at product conception, not post-deployment review.
The skills gap was underestimated in a specific way. The ML engineers who succeeded at scale were not necessarily the ones with the deepest research backgrounds — they were the ones who understood production systems well enough to build reliable pipelines. Hiring for production systems thinking, not just modeling expertise, was a lesson learned the hard way.
Premature optimization blocked progress. Several leaders mentioned over-engineering AI products before validating that the product had genuine product-market fit. Building a sophisticated ML infrastructure for a feature that doesn't deliver value is wasted work. Validating value before investing in infrastructure sophistication is the sequence that works.
Monitoring should have been built earlier. Teams that treated monitoring as a post-launch priority found that they lacked visibility into model behavior changes that occurred gradually — distribution shifts that didn't immediately trigger alerts but eroded performance over months.
Building the AI-Ready Engineering Organization
The technical work of AI scaling is inseparable from the organizational work. The leaders who build AI products that last have figured out how to structure teams, culture, and hiring to sustain AI capability over time.
Cross-disciplinary fluency is the foundational capability. ML engineers who understand product requirements — who can read a product brief, identify where model behavior matters, and translate that into evaluation criteria — are more valuable in AI product teams than pure modeling specialists. Product managers who understand ML constraints — what models can and cannot do reliably, what data requirements exist, what evaluation looks like — make better prioritization decisions. Building this fluency requires deliberate investment in cross-training.
The AI-first mindset is a leadership posture, not a technology choice. It means treating AI capability as a core engineering competency, investing in the infrastructure and tooling that makes AI product development fast and reliable, and creating organizational structures where AI product thinking is everyone's responsibility, not a specialist enclave.
The leadership frame — AI-first does not mean AI-only. It means building the organizational capability to evaluate where AI creates genuine value, and then executing those AI products with the same engineering rigor you would apply to any critical system.
Hiring for systems thinking over point-solution skills pays compounding returns. AI products are sociotechnical systems — they involve models, infrastructure, data pipelines, governance processes, and user behavior. The engineers who thrive in this environment think in systems, not in model architectures.
Fostering an experimentation culture matters. AI product development involves inherent uncertainty — you are often building systems whose behavior you cannot fully predict in advance. Teams that create safe-to-fail environments, with fast feedback loops and low-cost ways to test hypotheses, move faster and learn faster than teams that treat every AI deployment as a high-stakes commitment.
Ethical AI frameworks are increasingly non-optional. Bias detection in training data, fairness evaluation across demographic groups, and explainability (XAI) techniques for high-stakes applications are capabilities that mature AI organizations build proactively. Treating ethics as a compliance function rather than an engineering function is a pattern that creates technical debt and organizational risk.
Continuous team education is a competitive advantage in AI. The field moves faster than most engineering disciplines. Teams that build in time for learning — reading papers, evaluating new model releases, participating in the broader AI engineering community — maintain their capability edge over teams that treat education as optional.
Related Articles
- MLOps Best Practices for Production AI Systems
- Building RAG Systems That Scale
- AI Product Development: From Pilot to Production
- Evaluating LLM Applications: A Practical Framework