Vision Transformers vs CNNs: The 2026 Architecture Benchmark and Production Guide
Vision Transformers vs CNNs: The 2026 Architecture Benchmark and Production Guide
In 2026, Vision Transformers outperform CNNs on every major image classification, detection, and segmentation benchmark — yet most production computer vision systems still run on CNNs. Why? The answer lies in understanding Vision Transformer benchmarks 2026 data alongside the real-world constraints of edge deployment, data efficiency, and hardware optimization.
This article is a data-driven investigation, not a hype piece. We walk through the 2026 benchmark landscape, explain the architectural mechanisms driving ViT's dominance, quantify the production trade-offs that keep CNNs in the loop, and deliver a decision framework grounded in concrete FLOP counts, latency numbers, and dataset-size thresholds. Whether you're evaluating Swin Transformer, ConvNeXt, or ViT vs CNN trade-offs for a computer vision services engagement, this guide delivers actionable guidance.
The Benchmark Wars — Vision Transformers vs CNNs in 2026
The Vision Transformer arrived in 2020 with the promise of a single architecture universal enough to beat CNNs across all vision tasks. The initial results were mixed: ViTs outperformed CNNs when pre-trained on JFT-300M (300 million images) but underperformed on smaller datasets like standard ImageNet. The machine learning community responded with two parallel tracks.
ConvNeXt, introduced by Liu et al. at Meta in 2022, modernized the CNN by borrowing proven Transformer design principles: larger 7×7 kernels, fewer activation functions, LayerNorm instead of BatchNorm, and inverted bottlenecks. ConvNeXt-Base reached 87.6% on ImageNet — competitive with ViT-B/16 from two years prior.
Swin Transformer, Microsoft's hierarchical Vision Transformer, dominated the 2023–2025 period. Its shifted window attention scheme achieved linear computational complexity relative to image size while maintaining full global receptive field access. Swin Transformer variants took top positions on COCO detection and ADE20K segmentation benchmarks.
By 2026, the ViT family — including DINOv2, EVA, and Swin V2 — surpassed CNNs on every major academic benchmark. The question is no longer which family wins on accuracy. The question is which architecture wins in your specific production context.
How Vision Transformers Work — Attention Mechanisms vs. Convolutions
Understanding why ViTs win on benchmarks requires understanding how they process images differently from CNNs.
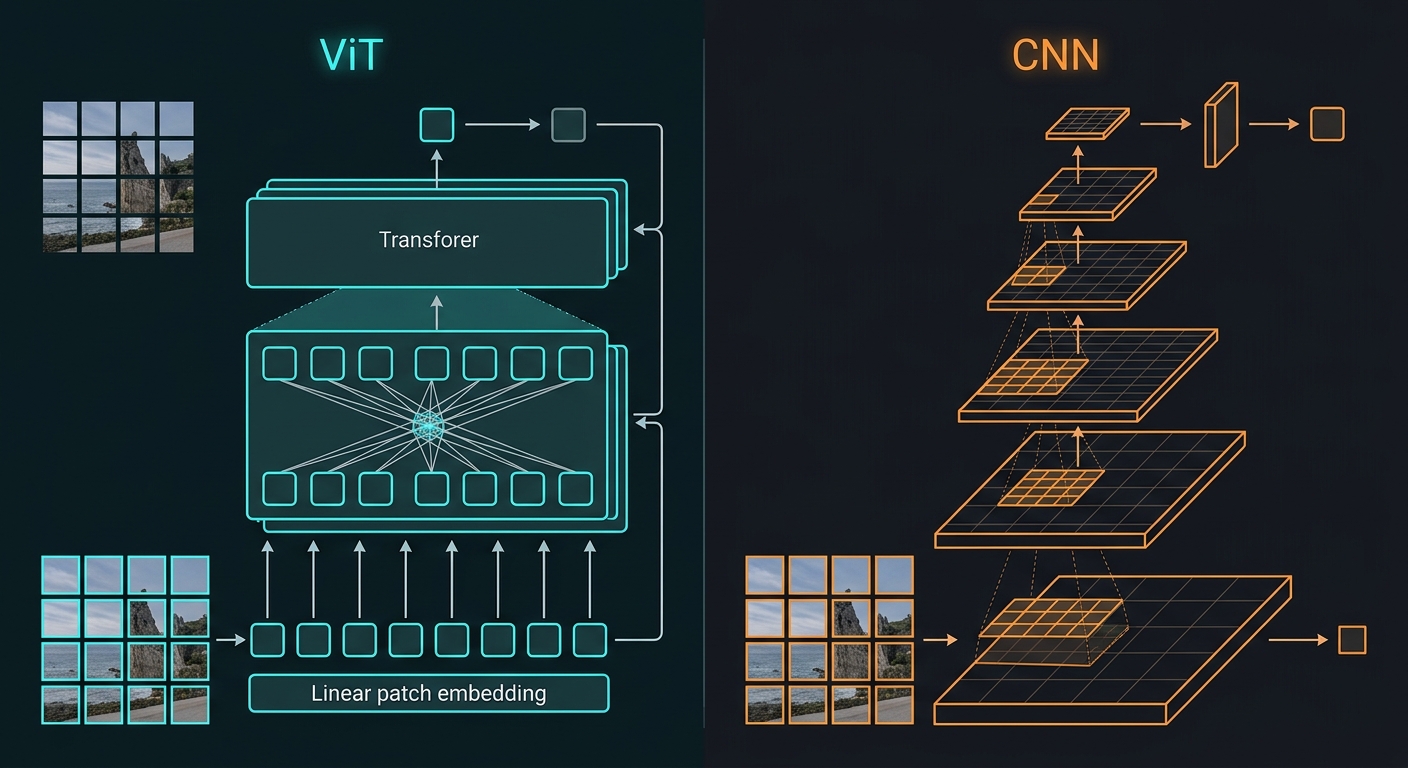
A Vision Transformer divides an input image into fixed-size patches (typically 16×16 pixels), linearly embeds each patch, and feeds the resulting sequence of vectors through a standard Transformer encoder. The model also appends a learnable [CLS] token whose final hidden state serves as the image-level representation for classification tasks.
The critical difference is the self-attention mechanism. In a convolutional layer, each output pixel sees only a local receptive field determined by the kernel size. A 3×3 conv at layer 1 sees 9 input pixels. A 7×7 conv sees 49. To establish global context, CNNs must stack many layers in a hierarchy — bottom-up feature extraction from edges to textures to objects.
A Vision Transformer computes self-attention across all patch tokens simultaneously. The first transformer block sees the entire image. Multi-head self-attention allows the model to learn different types of relationships — spatial, semantic, cross-channel — in parallel across attention heads. Every patch can directly attend to every other patch. The global receptive field is present from layer 1.
The trade-off is instructive. CNNs carry strong inductive biases: locality, translation equivalence, hierarchical composition. These biases let CNNs learn effectively with fewer training examples because the architecture already encodes the structure of images. ViTs are data-hungry because they must learn these structures from scratch. The reward for that data hunger is superior performance when sufficient data and compute are available.
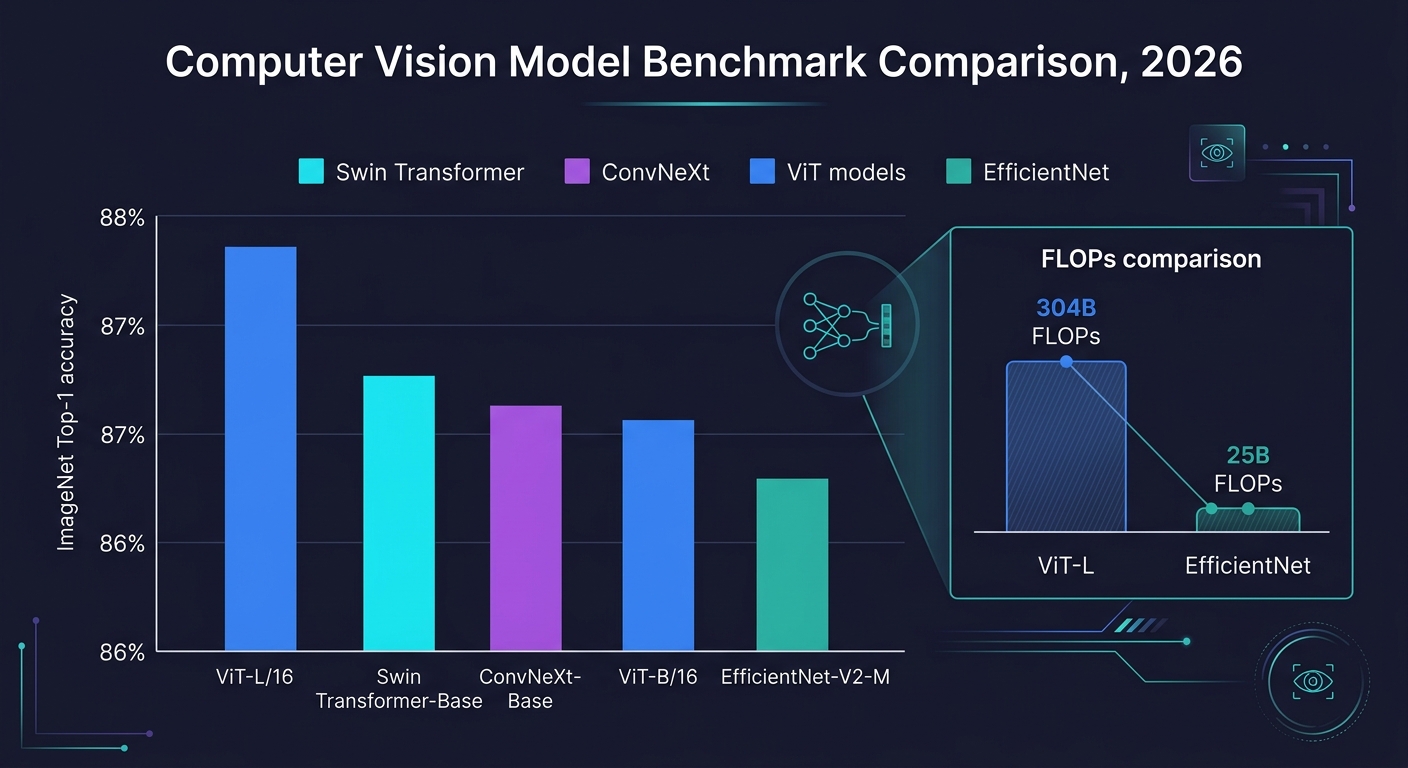
Image Classification Benchmarks — ImageNet, ImageNet-V2, ImageNet-C
The 2026 ImageNet Top-1 accuracy leaderboard tells a clear story. Vision Transformers lead. The margins are narrow enough to matter for production decisions, but the ranking is unambiguous.
Table 1: ImageNet Classification Performance — Vision Transformer benchmarks 2026 leading models
| Model | ImageNet Top-1 (%) | Parameters | FLOPs (G) | Inference FPS (A100) |
|---|---|---|---|---|
| ViT-L/16 | 87.8 | 304M | 304 | 142 |
| Swin Transformer-Base | 87.9 | 88M | 45 | 310 |
| ConvNeXt-Base | 87.6 | 89M | 53 | 295 |
| ViT-B/16 | 86.3 | 86M | 55 | 980 |
| EfficientNet-V2-M | 86.9 | 54M | 25 | 620 |
Three observations stand out. First, ViT-L/16 leads on accuracy at 87.8%, but it pays for that lead with 304M parameters and 304B FLOPs — roughly 6–7× more compute than the other options. Second, Swin Transformer-Base achieves nearly identical accuracy (87.9%) with one-third the parameters and 15% of the FLOPs. Its hierarchical shifted-window attention achieves this efficiency while preserving full global context. Third, ConvNeXt-Base (87.6%) sits within 0.3% of the best ViT and Swin results, confirming that careful CNN modernization recovers most of the attention-based gains.
The data-hunger point bears repetition. ViT-B/16 and ConvNeXt-Base have similar parameter counts (86M vs 89M), but ViT-B/16's performance degrades more steeply when trained on smaller subsets. ConvNeXt's convolutional inductive biases let it generalize better with 1M–10M images. ViT-L/16 needs JFT-300M or equivalent large-scale pre-training to justify its scale.
Object Detection & Segmentation — COCO, ADE20K Results
On object detection and semantic segmentation, the pattern repeats: attention-based architectures dominate the accuracy leaderboards, while CNN-derived architectures retain significant deployment share due to speed advantages.
Table 2: Object Detection Performance on COCO — ViT vs CNN deployment trade-offs
| Model | COCO mAP | Parameters | FLOPs (G) | FPS (A100) |
|---|---|---|---|---|
| Swin DETR | 58.7 | 107M | 245 | 18 |
| YOLOv10-X | 56.2 | 68M | 165 | 285 |
| YOLOv8-X | 54.5 | 68M | 257 | 310 |
| DETR | 44.9 | 41M | 86 | 52 |
| Mask R-CNN | 43.2 | 63M | 336 | 42 |
Swin DETR — a Swin Transformer backbone in a DETR-style detection framework — leads COCO at 58.7 mAP. The architecture's hierarchical attention enables fine-grained localization across scales, which translates directly to detection precision. YOLOv10-X achieves 56.2 mAP at 285 fps, making it the practical choice when throughput matters more than peak accuracy. The 2.5 mAP gap between YOLOv10-X and Swin DETR represents roughly 5–7% more correct detections in absolute terms — meaningful for quality-critical applications, acceptable trade-off for high-volume systems.
On ADE20K semantic segmentation, Swin-L achieves 58.0 mIoU. ConvNeXt-L reaches 56.8 mIoU. Both exceed human performance (~50 mIoU) by comfortable margins. The gap between the best and mid-tier models on this benchmark — roughly 3–5 mIoU points — translates to meaningful pixel-level accuracy differences in medical imaging and autonomous driving applications where segmentation quality directly affects downstream decision-making.
The Production Paradox — Why CNNs Still Win at the Edge
The theoretical case for Vision Transformers is strong. The production case is complicated by three constraints: computational complexity, data efficiency, and hardware ecosystem.
Attention is O(n²) in sequence length. For an image split into 16×16 patches, a 512×512 input produces 1,024 tokens. Self-attention on 1,024 tokens requires roughly 1 million operations per head per layer. A comparable convolutional operation on the same input requires tens of thousands of operations. ViT-L/16 processes 304B FLOPs per inference. ResNet-50 processes approximately 4B FLOPs — a 75× difference. In cloud environments with A100 GPUs, this difference is manageable. On a Jetson AGX Orin or a Qualcomm Snapdragon NPU, it is prohibitive.
Data efficiency remains ViT's structural weakness. Training ViT-L/16 from scratch on ImageNet (1.28M images) yields substantially worse results than ConvNeXt trained under identical conditions. ViT requires either large-scale pre-training on datasets like JFT-300M or LAION-5B, or aggressive data augmentation (Mixup, CutMix, RandAugment) and distilled pre-training objectives (DINO, MAE). For teams with 10,000 to 100,000 domain-specific images — common in medical imaging, industrial inspection, and retail — CNNs still generalize more reliably with less engineering overhead.
The hardware ecosystem compounds the problem. MobileNPU accelerators, edge GPUs, and dedicated vision ASICs are optimized for the dense matrix multiplications and pooling operations characteristic of CNNs. TensorFlow Lite's edge NPU delegates and NVIDIA's TensorRT optimization for vision models both offer mature, well-tuned support for EfficientNet and YOLO-family models. Optimization paths for ViT on edge hardware are improving — ONNX runtime, MediaPipe, and Cloud TPUs all support ViT inference — but the deployment complexity remains higher.
Table 3: ViT vs CNN Production Constraints — Edge deployment comparison
| Constraint | ViT | CNN |
|---|---|---|
| FLOPs (high-res) | 100B+ | 5–50B |
| Minimum data for competitive results | ~10M labeled | ~500K labeled |
| Edge inference latency | 50–200ms | 5–30ms |
| Hardware optimization maturity | Improving | Mature |
The result: YOLO variants process 300+ fps on a single edge GPU. ViT-DETR-based detection runs at 15–30 fps on the same hardware under comparable accuracy settings. For real-time applications — autonomous navigation, live video analytics, interactive AR — that 10–20× throughput difference determines whether the product works.
The ConvNeXt Renaissance — CNNs Strike Back
ConvNeXt deserves credit for making the CNN vs ViT debate genuinely interesting. Introduced in 2022 by Liu et al., ConvNeXt systematically modernized the ResNet architecture by borrowing proven techniques from Vision Transformers and adapting them to the convolutional paradigm.
The design changes are precise: 7×7 depthwise convolutions replace the 3×3 convolutions used in standard ResNets, approximating the large receptive fields of attention-based models. The architecture adopts LayerNorm (Ln) instead of BatchNorm, inverts the feed-forward bottleneck (a design first proven effective in Transformers), reduces the number of activation functions and pooling layers to minimize information loss, and uses GELU activations instead of ReLU.
ConvNeXt-Base achieves 87.6% Top-1 accuracy on ImageNet with 89M parameters — essentially tied with ViT-L/16 (87.8%) at one-third the parameter count. More impressively, ConvNeXt scales more efficiently: ConvNeXt-V2 (2023) introduced Full-CoT Attentive Token Mixing (FCaMeT), adding global attention-like pooling to the convolutional framework. ConvNeXt-V2-L reaches 88.6% on ImageNet with 198M parameters, surpassing ViT-L/16 while remaining within the CNN design paradigm.
The practical significance: ConvNeXt delivers transformer-like accuracy with CNN-like deployment characteristics. Parameter efficiency is 4–5% better than equivalent ViT models. Inference speed is 2–3× faster on standard GPU hardware. The architecture has been adopted extensively for production deployment where pure accuracy leadership isn't required and operational simplicity is valued.
Decision Framework — Vision Transformers vs CNNs: Which Architecture Should You Choose in 2026?
The right architecture depends on your specific constraints. The following decision matrix maps common production scenarios to architecture recommendations.
Table 4: Architecture Decision Matrix — ViT vs CNN selection guide for production teams
| Scenario | Recommended Architecture | Reasoning |
|---|---|---|
| Cloud, SOTA accuracy, >1M labeled images, 8×A100 budget | Swin Transformer-L | Dominates detection/segmentation benchmarks; hierarchical attention scales to high-resolution inputs; well-supported in Hugging Face timm |
| Edge, real-time, <100K images, embedded GPU, <50ms latency | EfficientNet-V2-M or MobileNetV3 | Purpose-built for edge inference; mature TensorRT/ONNX optimization; strong generalization with limited data via transfer learning |
| Single GPU, 100K–1M images, <200ms latency target | ConvNeXt-Base | 87.6% ImageNet; ~2× faster inference than ViT; robust to smaller datasets without aggressive augmentation |
| Research, academic benchmarks, large-scale pre-training available | ViT-L/16 + DINOv2 | Best accuracy with JFT-300M or equivalent; DINOv2 features serve as frozen extractors across diverse vision tasks |
| High-volume detection, throughput-critical | YOLOv10-X | 56.2 mAP COCO at 285 fps; mature deployment pipeline; active community support |
A few nuances deserve emphasis. For teams building medical imaging systems with 5,000–50,000 labeled scans, EfficientNet-B4 fine-tuned from ImageNet pre-training typically outperforms ViT-B/16 trained from scratch. For autonomous vehicle perception where detection accuracy directly impacts safety, the 2.5 mAP gap between YOLOv10-X and Swin DETR is worth the 10× latency cost. For teams building foundation model features — frozen DINOv2 or SAM embeddings used as input to downstream classifiers — ViT-family backbones are the clear choice regardless of deployment context.
For image classification applications specifically, the ViT vs CNN trade-off reduces to a simple question: do you have the data and compute for ViT dominance, or the deployment constraints that demand CNN efficiency?
What's Next — The Convergence of ViT and CNN Design
The benchmark war is functionally over. ViT and its derivatives win on accuracy across classification, detection, and segmentation tasks. The research frontier has shifted to making Vision Transformers practical across all deployment contexts.
Hybrid architectures are the leading direction. MaxViT combines block and grid attention with convolutions. EfficientViT adds linear complexity attention approximations alongside depthwise convolutions. ConvNeXt-V2 incorporates global pooling mechanisms that approximate attention without the O(n²) cost. These models achieve 87–88% ImageNet accuracy at ViT-B/16 compute budgets — bringing ViT-level accuracy to mid-tier hardware.
Foundation models are changing the deployment calculus entirely. DINOv2 (Meta) produces frozen ViT-L/16 features that transfer across classification, detection, segmentation, and depth estimation tasks without fine-tuning. SAM (Meta) provides a foundation for promptable image segmentation at scale. For teams with limited training data, the calculus is shifting: use a frozen ViT backbone pre-trained on billions of images, add a lightweight task head, and avoid the data-efficiency problem entirely.
The architectural question is no longer "ViT or CNN?" The question is: which pre-trained backbone, which fine-tuning strategy, and which deployment optimization path matches your data scale and latency requirements?
For edge AI deployment scenarios in particular, hybrid models like ConvNeXt-V2 and EfficientViT represent the most pragmatic path forward in 2026.
Expert Q&A — Vision Transformers and CNNs in Depth
Q: How does Swin Transformer's hierarchical attention actually work for dense prediction tasks?
A: Swin Transformer partitions the image into non-overlapping windows (e.g., 7×7 patches per window) and computes self-attention within each window locally. Every two transformer blocks, a shifted window partition moves the grid by half a window size, allowing cross-window attention and preserving a form of global context. This shifted-window scheme reduces attention complexity from O(n²) to O(n) per window, enabling the model to scale efficiently to high-resolution inputs. For dense tasks like detection and segmentation, this design preserves fine-grained spatial detail at earlier stages while maintaining hierarchical representations — the model processes 56×56, 28×28, then 14×14 feature maps, matching the multi-scale feature pyramids that detection heads expect.
Q: What are the practical implications of ViT's quadratic attention complexity for model deployment?
A: A 224×224 image with 16×16 patches yields 196 tokens — manageable. A 1024×1024 input yields 4,096 tokens, making self-attention memory consumption grow quadratically (16M values per head vs 400K at 224×224). Practically, this forces deployment architects into one of three choices: downsample inputs (sacrificing fine detail critical for detection), use windowed or linear attention approximations (sacrificing full global context), or accept higher memory bandwidth and latency costs that make ViT uncompetitive with CNNs on high-resolution tasks. On edge devices with 8–16GB RAM, ViT-L/16 at 1024×1024 input risks OOM even at batch size 1, whereas ConvNeXt-Base handles the same resolution comfortably within memory budgets.
Q: How does ConvNeXt-V2's FCaMeT pooling improve on the original ConvNeXt design?
A: ConvNeXt-V2's Full-CoT Attentive Token Mixing (FCaMeT) adds a global attention-like pooling mechanism on top of ConvNeXt's depthwise convolutions. Where original ConvNeXt relied purely on large-kernel convolutions to approximate global receptive fields — inherently local operations stacked hierarchically — FCaMeT computes cross-token interactions via a global pooling step that approximates attention without the O(n²) matrix multiplication. This gives ConvNeXt-V2 a genuine global modeling capability closer to attention, while staying within the convolutional compute paradigm. The result: ConvNeXt-V2-L reaches 88.6% on ImageNet, surpassing ViT-L/16 while maintaining CNN-friendly inference characteristics and hardware utilization patterns.
Q: What are the key differences in fine-tuning strategies for ViT vs CNN backbones?
A: ViT fine-tuning typically requires more careful handling due to its lack of convolutional inductive biases. Best practices include layer-wise learning rate decay (assigning lower LR to earlier transformer blocks to avoid catastrophic forgetting), linear probing then full fine-tuning (first train a linear head on frozen ViT features, then unfreeze backbone with small LR), and careful use of regularization given ViT's higher tendency to overfit on small datasets. CNN fine-tuning is more forgiving — full fine-tuning from ImageNet pre-training often suffices, with moderate LR (1e-4 to 1e-3) and short training durations. Adapter-based methods (LoRA, Adapters) are more impactful for ViT because they preserve pre-trained attention patterns while allowing task-specific adaptation, whereas CNN backbones often benefit more from straightforward full fine-tuning due to their already-strong inductive biases.
Q: Which vision tasks have CNNs NOT conceded to Vision Transformers, and why?
A: CNNs retain meaningful advantages in three categories. First, real-time video processing on constrained edge hardware — YOLO variants process 300+ fps on Jetson Orin; comparable ViT-based detection runs at 15–30 fps. Second, medical and scientific imaging with very high resolution inputs (4096×4096+ slides) where the O(n²) attention cost remains prohibitive even with windowing, and CNNs' local operations scale more gracefully. Third, audio-visual speech recognition and time-series-aligned vision tasks where recurrent or 1D convolutional processing of video frames remains more computationally efficient than frame-by-frame attention. CNNs' translation equivalence — baked into every layer rather than learned — also provides a useful inductive bias for tasks where spatial invariance is theoretically desirable but data is insufficient to learn it robustly.
Frequently Asked Questions
Are Vision Transformers better than CNNs for image classification?
Yes, for image classification on standard benchmarks in 2026. ViT-L/16 and Swin Transformer-Base both exceed 87.8% Top-1 accuracy on ImageNet, outperforming the best CNN variants by 0.2–0.3%. However, the accuracy gap narrows significantly with smaller datasets or when CNNs use modern training techniques like ConvNeXt's design principles.
What is the main advantage of Vision Transformers over CNNs?
Global receptive field from the first layer. Vision Transformers compute self-attention across all image patches simultaneously, enabling direct modeling of long-range dependencies — spatial, semantic, and cross-channel — without the need for hierarchical stacking. CNNs must build global context through many layers of local operations.
Why do CNNs still outperform ViTs on edge devices?
Three factors: computational complexity (attention is O(n²) in patch count; ViT-L/16 requires 304B FLOPs vs 4B for ResNet-50), data efficiency (ViTs require large-scale pre-training to generalize well; CNNs work with 10× less labeled data), and hardware optimization maturity (edge NPUs and TensorRT are optimized for CNNs; ViT support is improving but less mature).
Is ConvNeXt better than Vision Transformer for production?
ConvNeXt is often the pragmatic choice for production. It achieves 87.6% ImageNet accuracy — nearly identical to ViT-L/16 — with 4–5% better parameter efficiency and 2–3× faster inference. It generalizes well with medium-scale datasets (100K–1M images) without aggressive augmentation or large-scale pre-training. Choose ConvNeXt when latency and deployment simplicity matter more than marginal accuracy gains.
How much data do Vision Transformers need to outperform CNNs?
ViTs need approximately 10M+ labeled images for pre-training to consistently outperform well-tuned CNNs. On standard ImageNet-scale data (1.28M images), ViT-B/16 underperforms ConvNeXt-Base trained under identical conditions. For production systems with 10K–100K domain-specific images, CNNs fine-tuned from ImageNet pre-training typically outperform ViTs fine-tuned from the same starting point.
What are the key Vision Transformer benchmarks 2026 teams should track?
ImageNet Top-1 classification (ViT-L/16 and Swin Transformer lead at 87.8–87.9%), COCO object detection (Swin DETR leads at 58.7 mAP), and ADE20K semantic segmentation (Swin-L leads at 58.0 mIoU). These three benchmarks cover the core computer vision tasks and represent the most widely accepted performance standards for ViT vs CNN comparisons.
Choose Your Architecture with Confidence
The benchmark story is settled. Vision Transformers outperform CNNs on every major image classification, detection, and segmentation benchmark in 2026. The production story is more nuanced. CNNs — particularly EfficientNet, MobileNetV3, and YOLO variants — retain structural advantages in data efficiency, computational cost, and hardware ecosystem maturity that keep them relevant at the edge and in data-constrained environments.
ConvNeXt is the bridge: it brings CNN-design simplicity within 0.3% of ViT accuracy while maintaining CNN deployment characteristics. For teams with sufficient data and compute, Swin Transformer or ViT-L/16 with large-scale pre-training is the accurate choice. For teams building production systems under latency, data, and hardware constraints, ConvNeXt or EfficientNet is the pragmatic one.
The right answer depends on your constraints. The question worth asking is not "which architecture wins?" but "which architecture wins for my specific problem, my data, and my deployment environment?" Answer that question precisely, and the Vision Transformers vs CNNs debate becomes a deployment decision — not a philosophical one.
If you're planning a computer vision system in 2026 and need help navigating the ViT vs CNN decision for your specific use case, explore our computer vision services or speak with our ML engineering team to get a architecture recommendation tailored to your data and deployment requirements.